MYSQL#
DDL 数据定义语言#
数据库相关命令#
CREATE DATABASE IF NOT EXISTS myDB; -- 创建数据库
USE myDB; -- 使用当前数据库
DROP DATABASE myDB; -- 删除数据库
表相关命令#
显示表#
SHOW TABLES;
创建表#
CREATE TABLE employees (
employee_id INT,
first_name VARCHAR(50),
last_name VARCHAR(50),
hourly_pay DECIMAL(5,2),
hire_date DATE
);
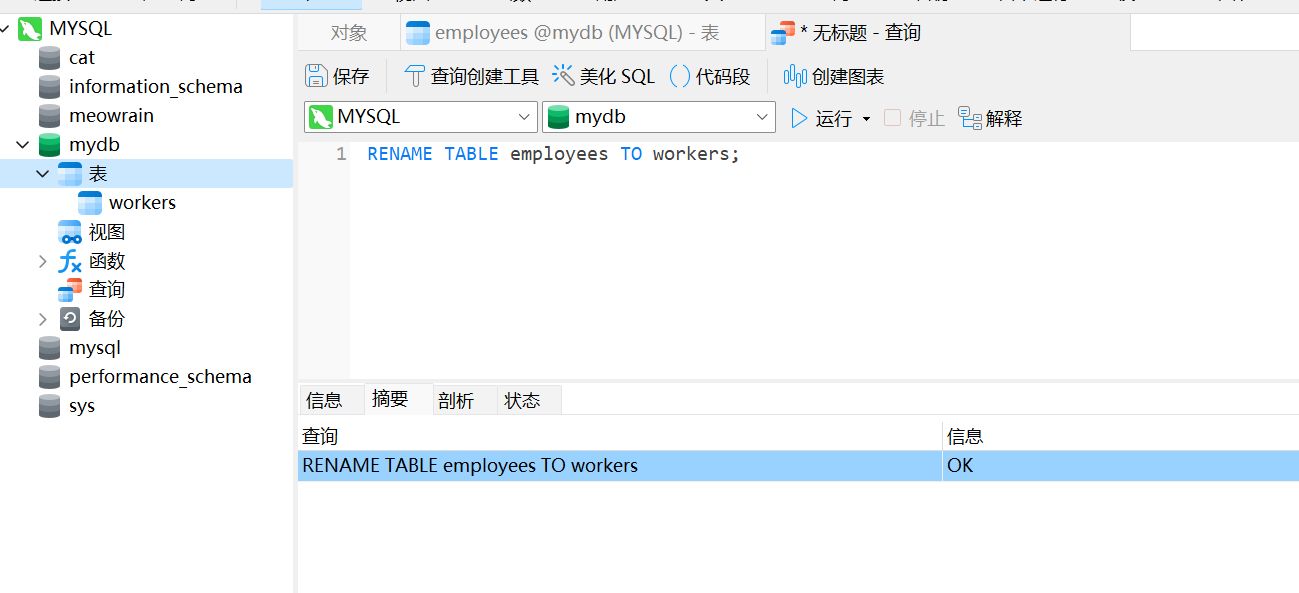
重命名表#
RENAME TABLE employees TO workers;
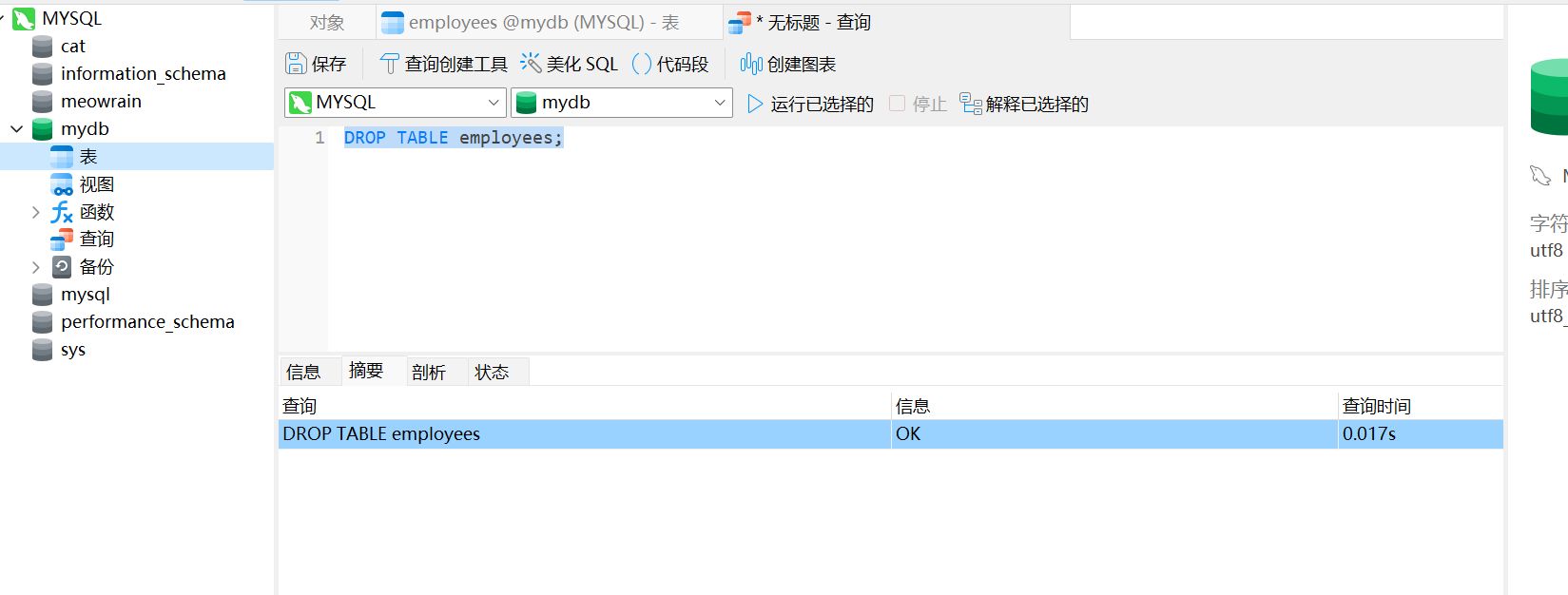
删除表#
DROP TABLE employees;
更改表#
ALTER TABLE employees
ADD phone_number VARCHAR(15);
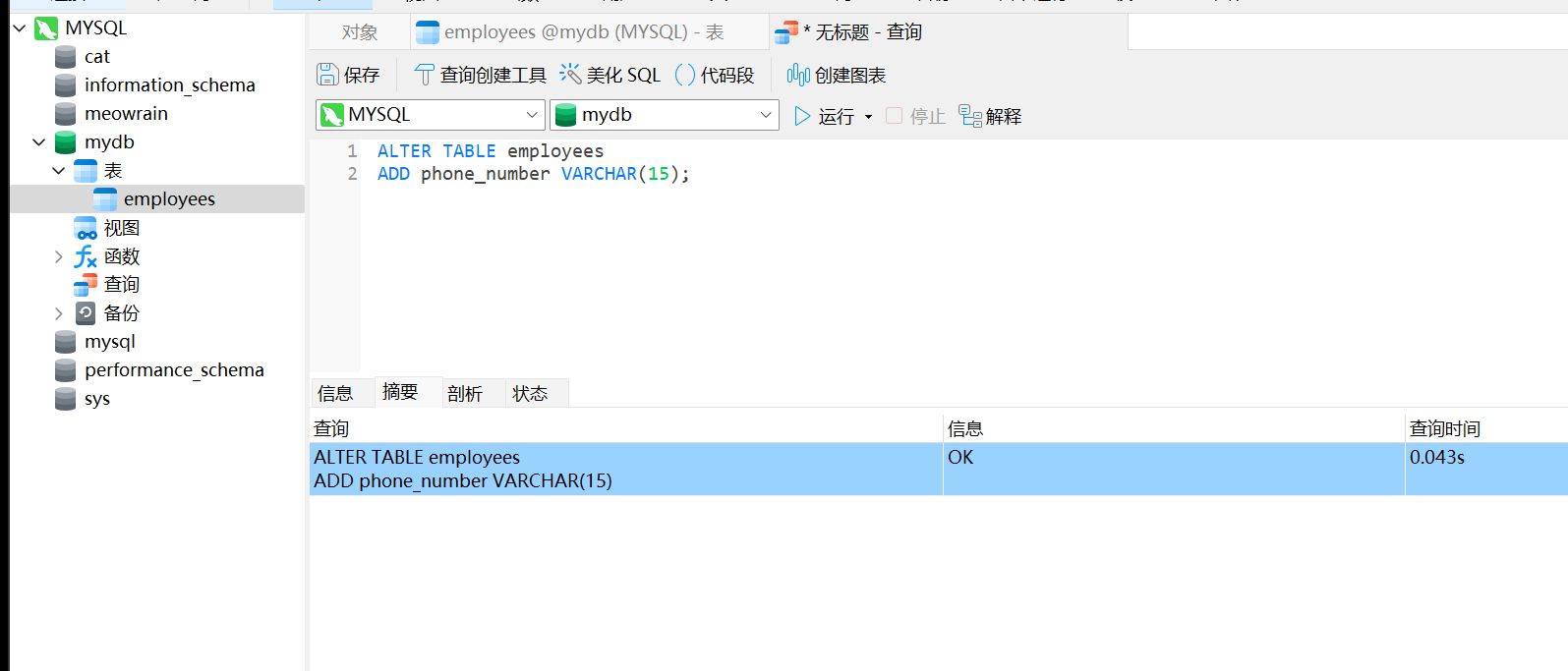
修改字段名
ALTER TABLE employees
CHANGE COLUMN `email` `emails` varchar(120) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL AFTER `phone_number`;
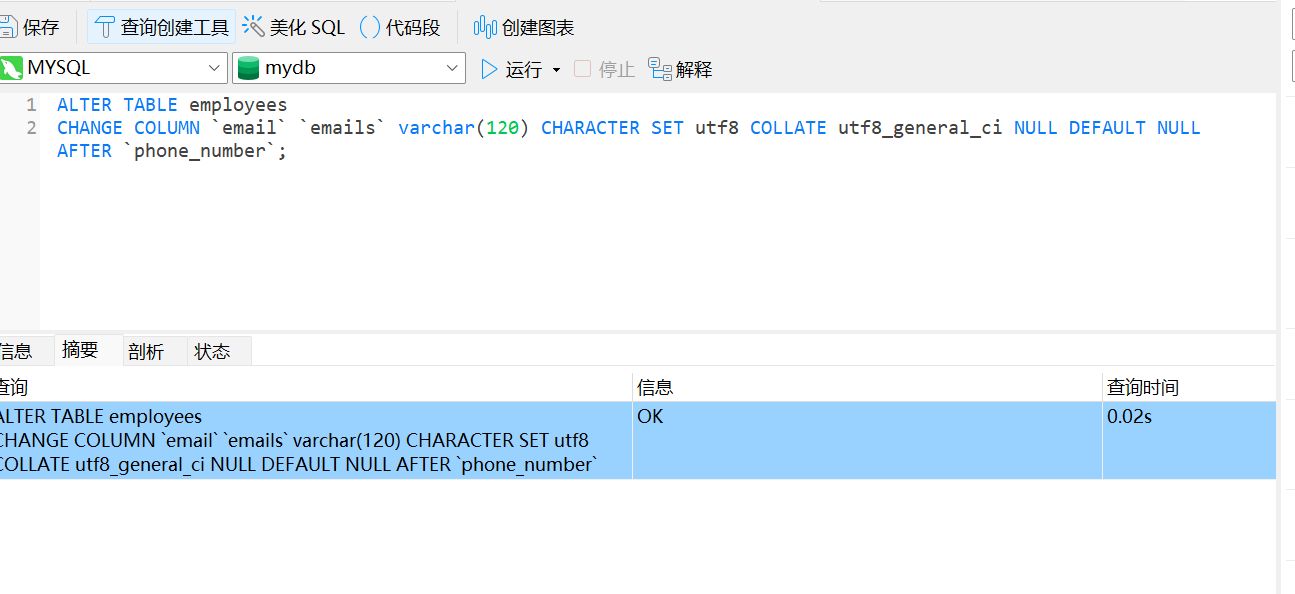

修改字段数据类型
ALTER TABLE employees
MODIFY COLUMN `email` VARCHAR(300);
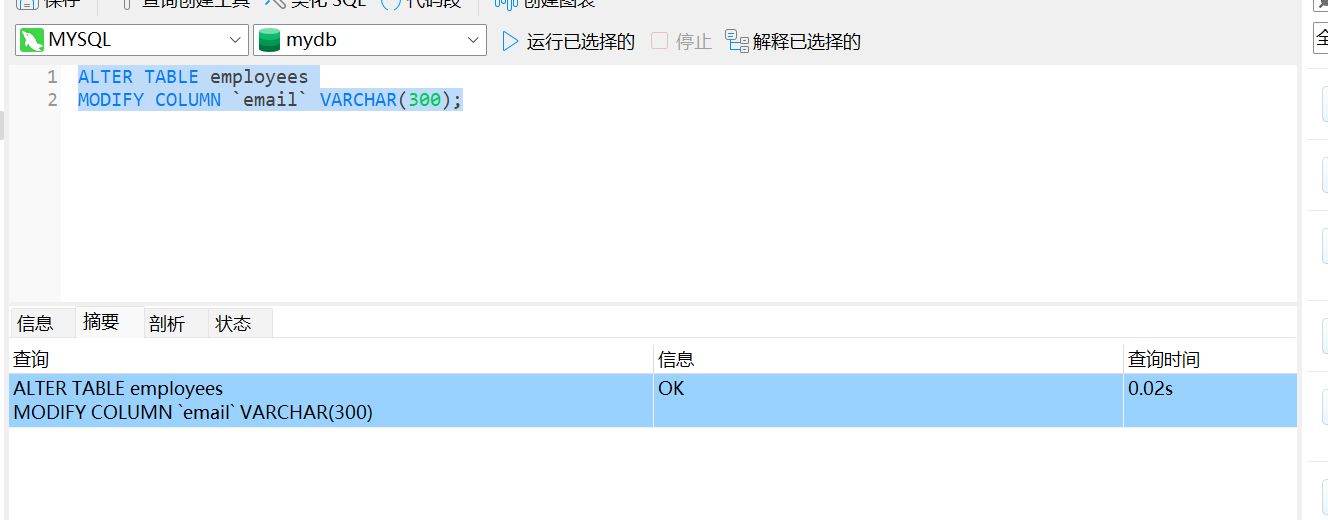
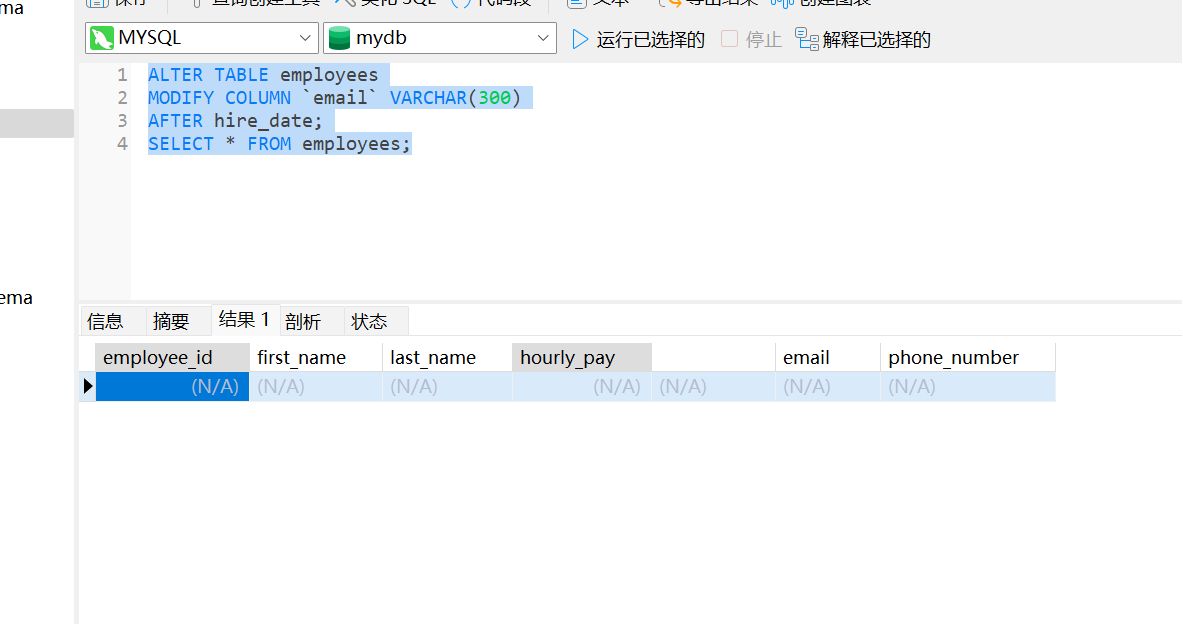
移动字段名位置
ALTER TABLE employees
MODIFY COLUMN `email` VARCHAR(300)
AFTER hire_date;
SELECT * FROM employees;
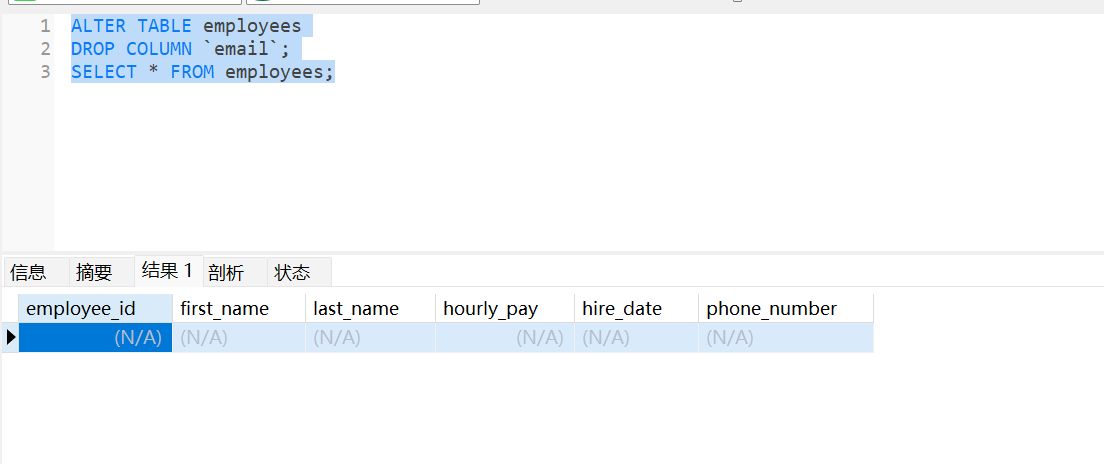
删除字段名
ALTER TABLE employees
DROP COLUMN `email`;
SELECT * FROM employees;
DML 数据操作语言#
插入数据#
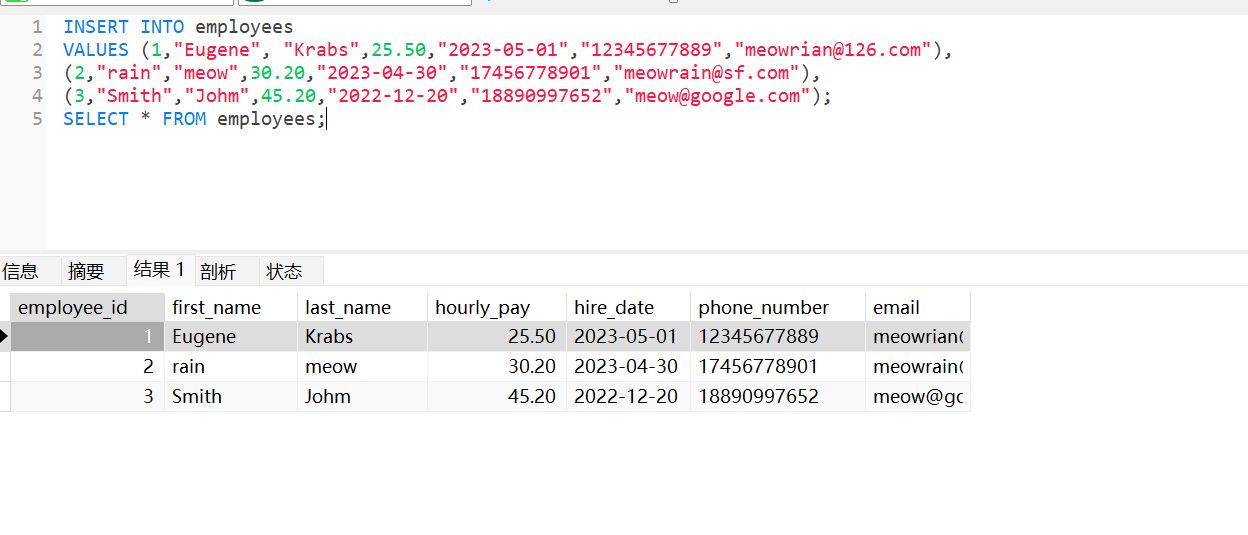
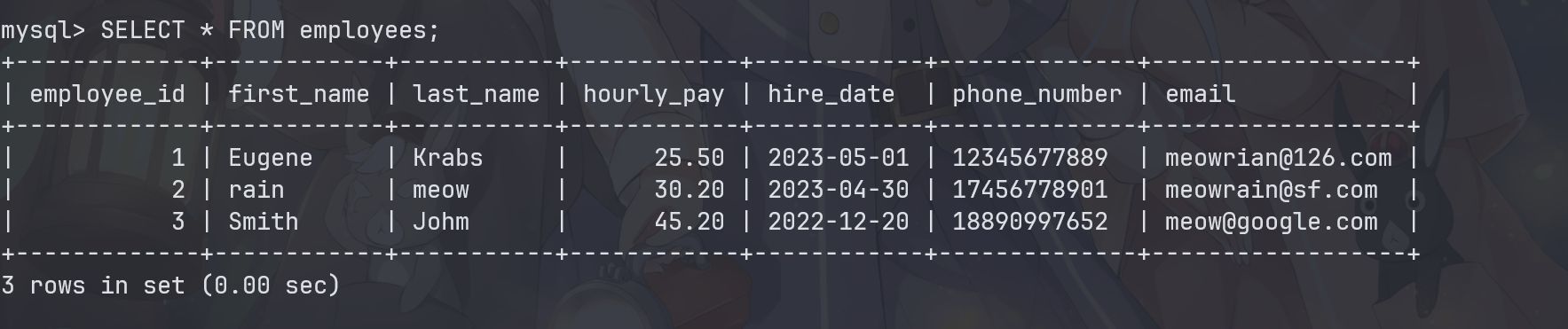
INSERT INTO employees
VALUES
( 1, "Eugene", "Krabs", 25.50, "2023-05-01", "12345677889", "meowrian@126.com" ),
( 2, "rain", "meow", 30.20, "2023-04-30", "17456778901", "meowrain@sf.com" ),
( 3, "Smith", "Johm", 45.20, "2022-12-20", "18890997652", "meow@google.com" );
SELECT * FROM employees;
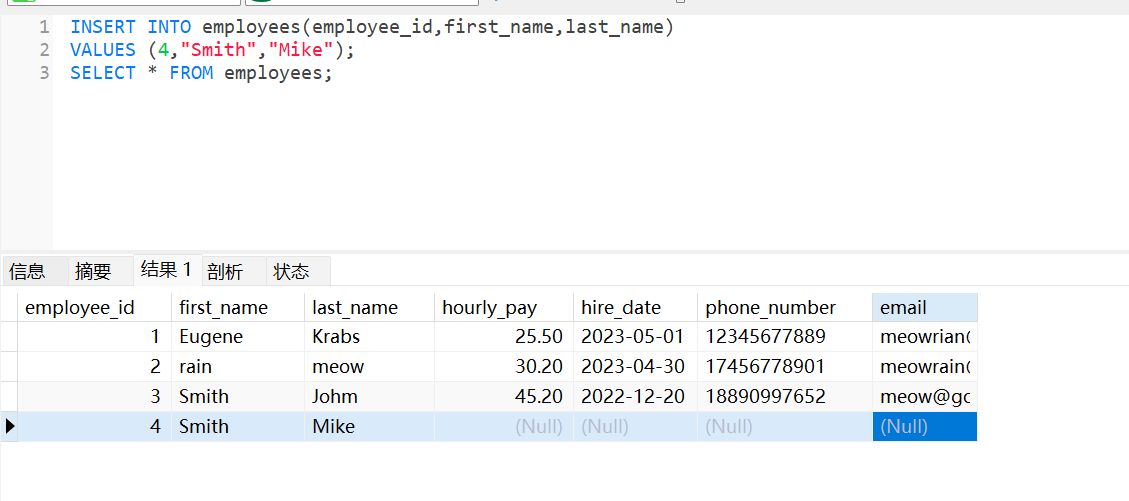
插入部分数据
INSERT INTO employees(employee_id,first_name,last_name)
VALUES (4,"Smith","Mike");
SELECT * FROM employees;
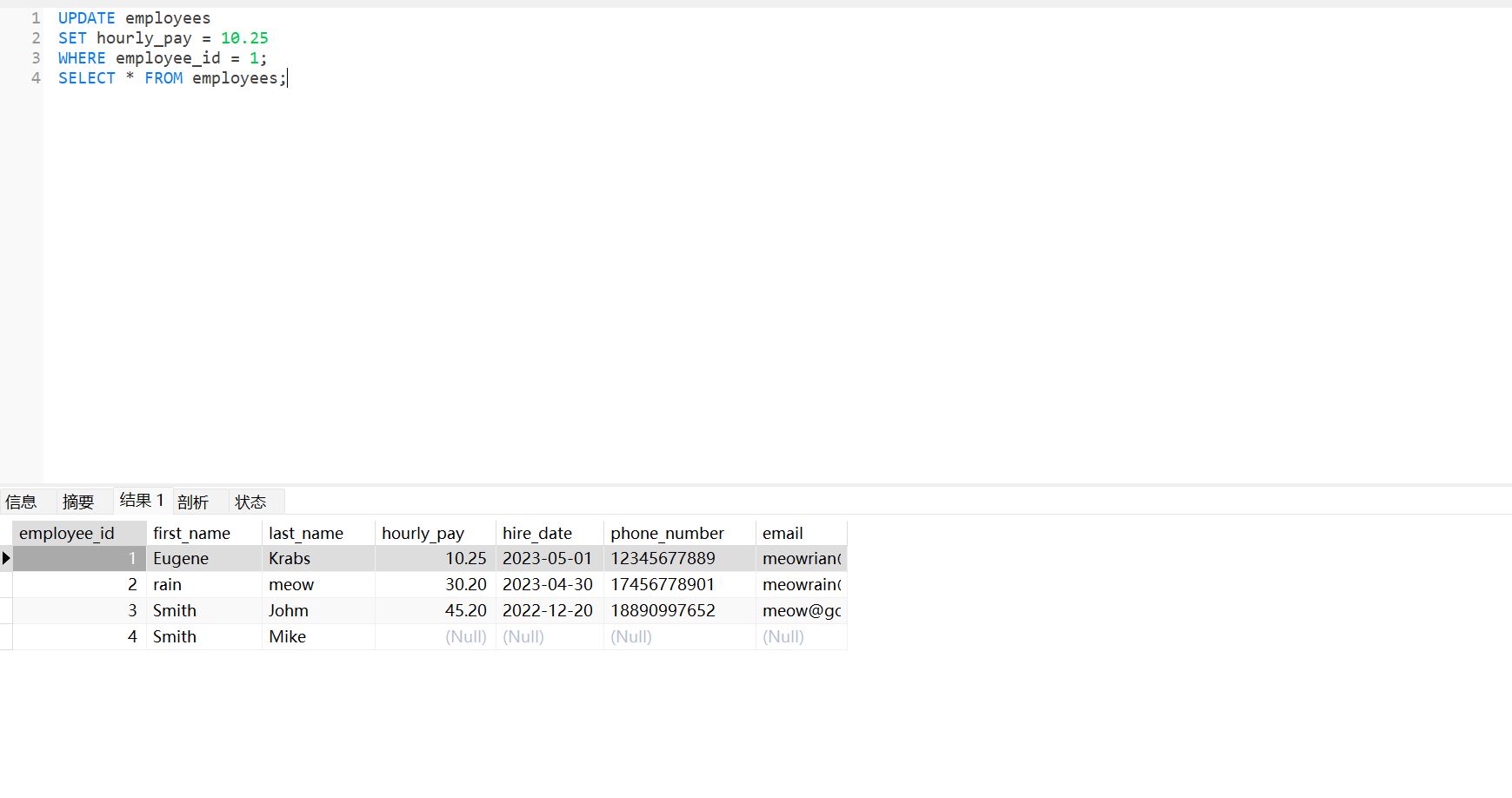
修改数据 UPDATE#
UPDATE employees
SET hourly_pay = 10.25
WHERE employee_id = 1;
SELECT * FROM employees;
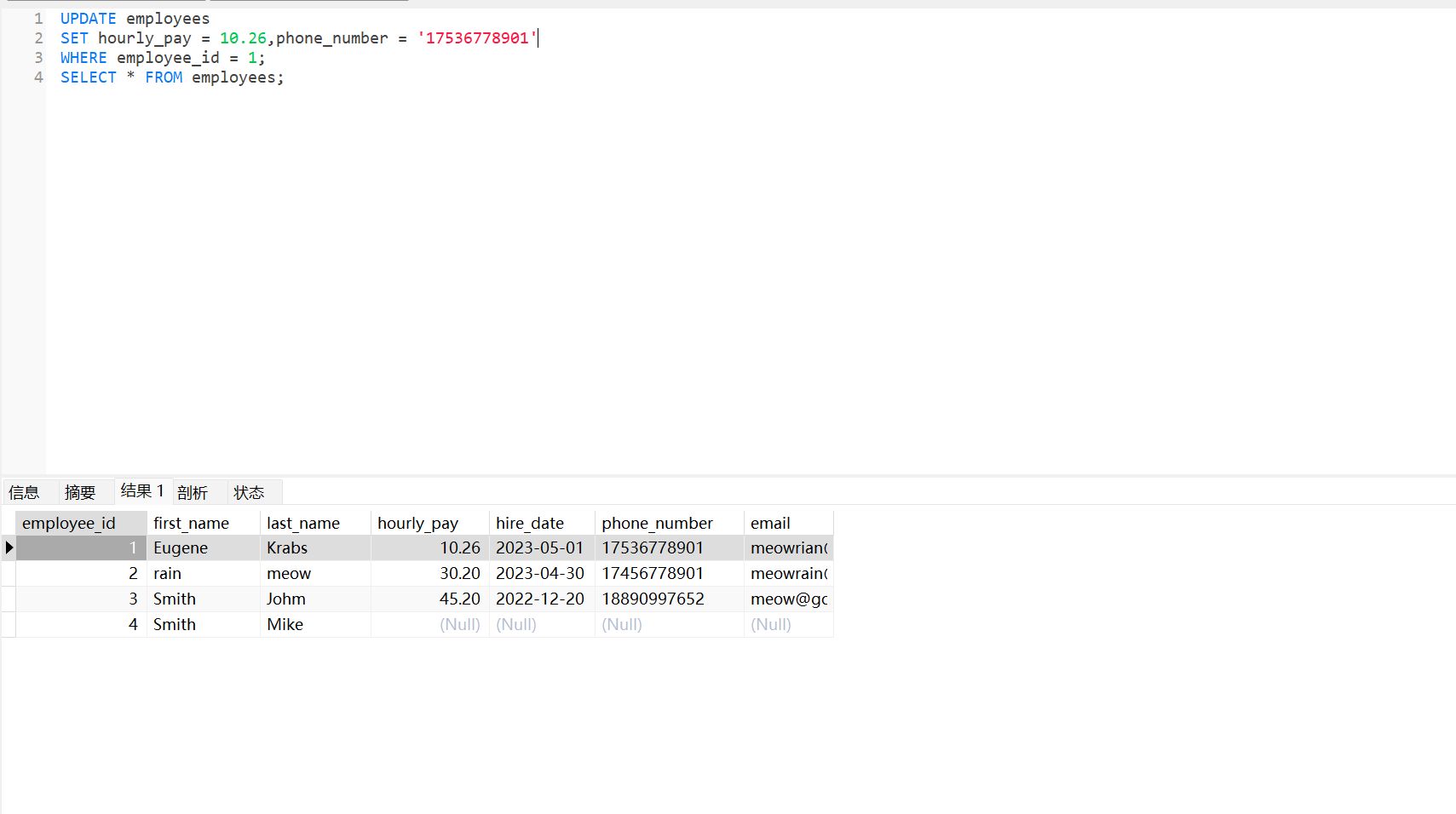
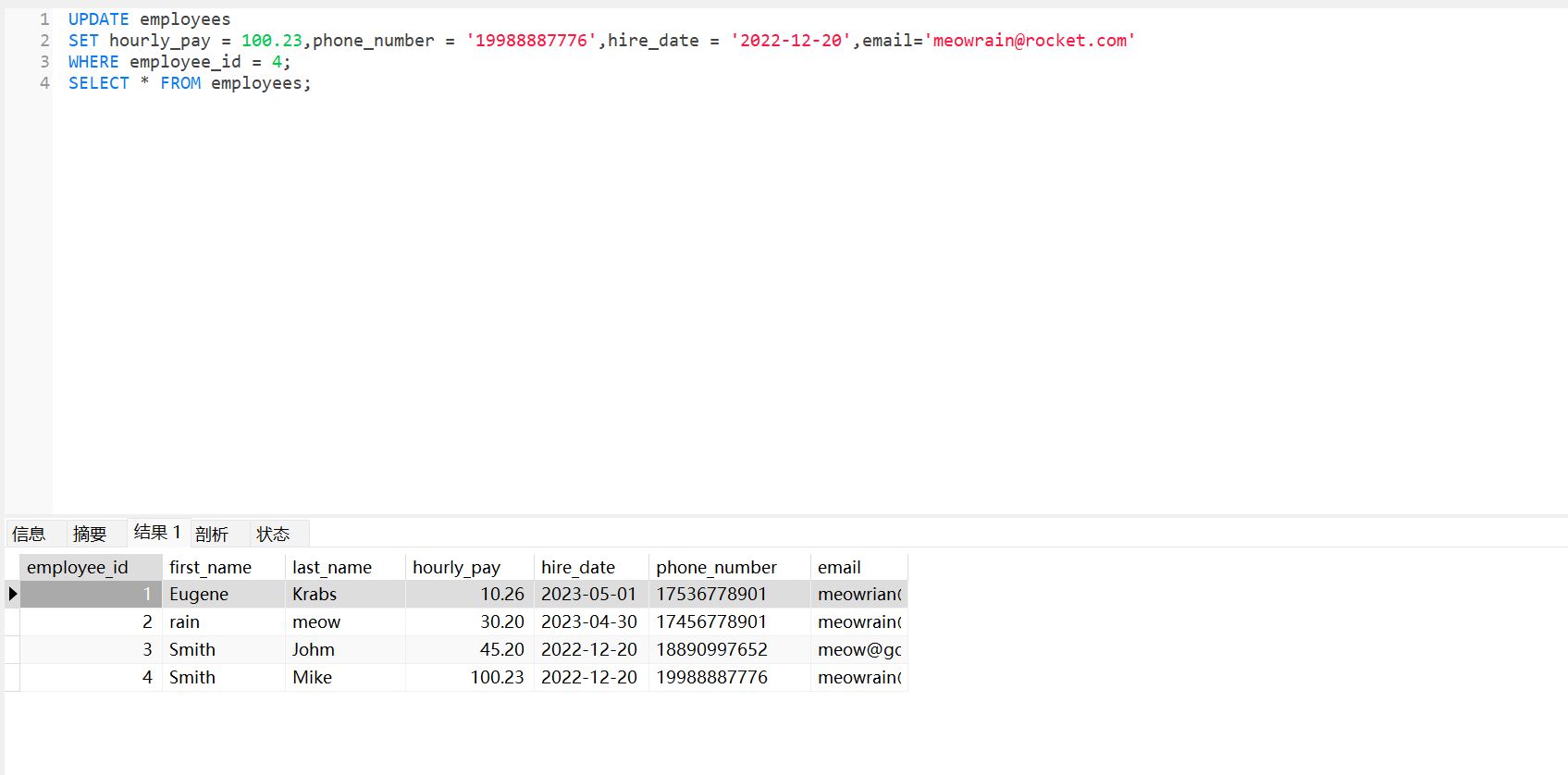
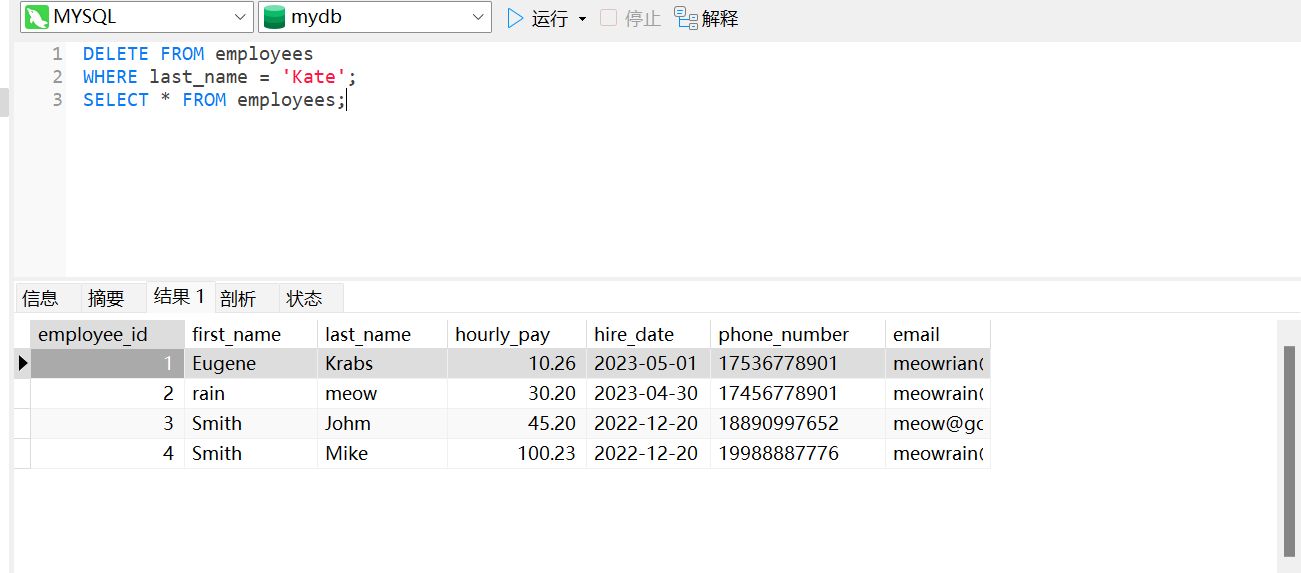
删除数据 DELETE#
DELETE FROM employees
WHERE last_name = 'Kate';
SELECT * FROM employees;
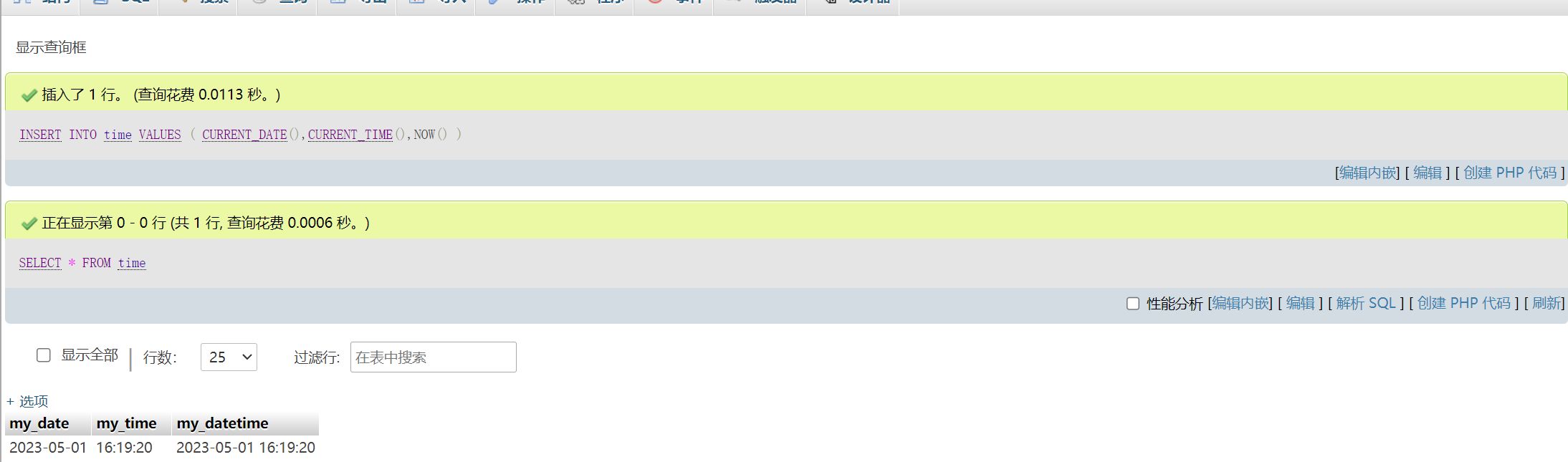
插入时间数据
创建表
CREATE TABLE time(
my_date DATE,
my_time TIME,
my_datetime DATETIME
);

SELECT * FROM time;

插入数据,并且查询结果
INSERT INTO time
VALUES (
CURRENT_DATE(),CURRENT_TIME(),NOW()
);
SELECT * FROM time;
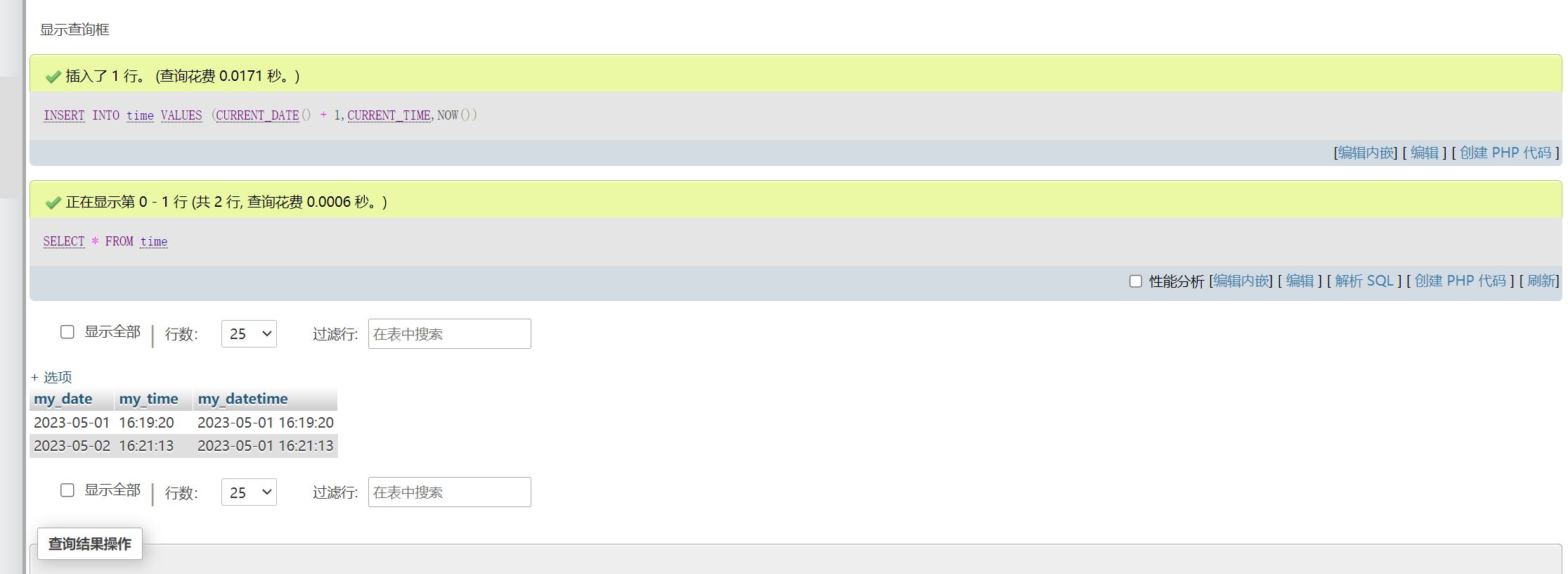
这样可以插入第二天的日期数据
DQL 数据查询语言#
SELECT 查询语句#
SELECT first_name, last_name FROM employees;
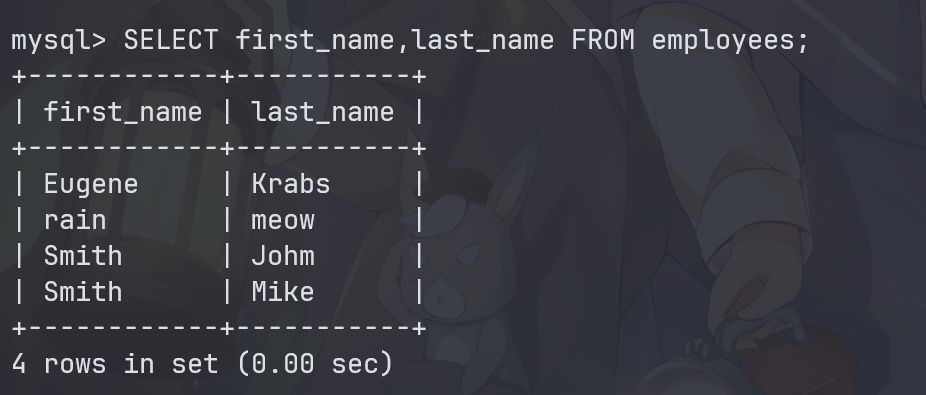
通过上面的这个命令,我就能拿到数据库中已经存储的所有人名了
SELECT + WHERE#
SELECT * FROM employees WHERE employee_id = 1;

通过上面的命令,我们就能获取到 id 为 1 的这个员工的所有数据了,当然了,我们也可以用名字查找
SELECT * FROM employees WHERE first_name = 'Eugene' AND last_name = 'Krabs';

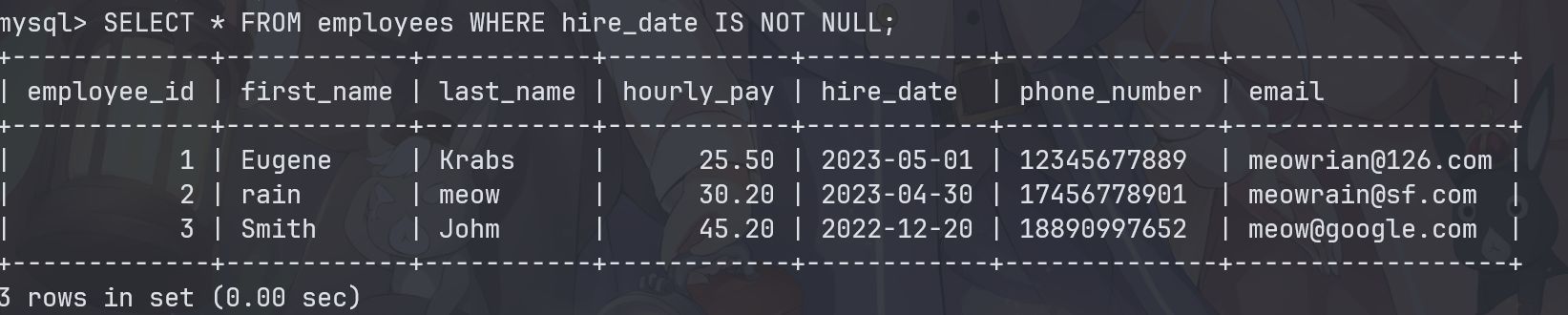
也可以用下面这个命令找到雇佣日期不是 NULL 的所有人的信息
SELECT * FROM employees WHERE hire_date IS NOT NULL;
关于 UNIQUE#
在创建表时, UNIQUE 关键字用于指定一个或多个列的值必须唯一。
CREATE TABLE products (
product_id INT,
product_name VARCHAR(25) UNIQUE,
price DECIMAL(4,2)
);
-- 在创建表时, UNIQUE 关键字用于指定一个或多个列的值必须唯一。在这里的例子中, UNIQUE 关键字强制 product_name 列中的每个值都是唯一的,这意味着不能有相同的 product_name 值存在于该表中的不同行中。如果插入的数据违反此限制,将会出现唯一键冲突错误。
CREATE TABLE products (
product_id INT,
product_name VARCHAR(25),
price DECIMAL(4,2)
);
-- 在创建表时, UNIQUE 关键字用于指定一个或多个列的值必须唯一。在这里的例子中, UNIQUE 关键字强制 product_name 列中的每个值都是唯一的,这意味着不能有相同的 product_name 值存在于该表中的不同行中。如果插入的数据违反此限制,将会出现唯一键冲突错误。
ALTER TABLE products
ADD CONSTRAINT
UNIQUE(product_name);
-- 这是一个 SQL 语句,它的意思是在名为 "products" 的表中添加一个名为 "product_name" 的唯一约束 (UNIQUE CONSTRAINT)。这意味着在该表中,每个产品名称只能出现一次。如果尝试插入具有相同产品名称的行,则会触发唯一约束,从而防止错误数据的插入。
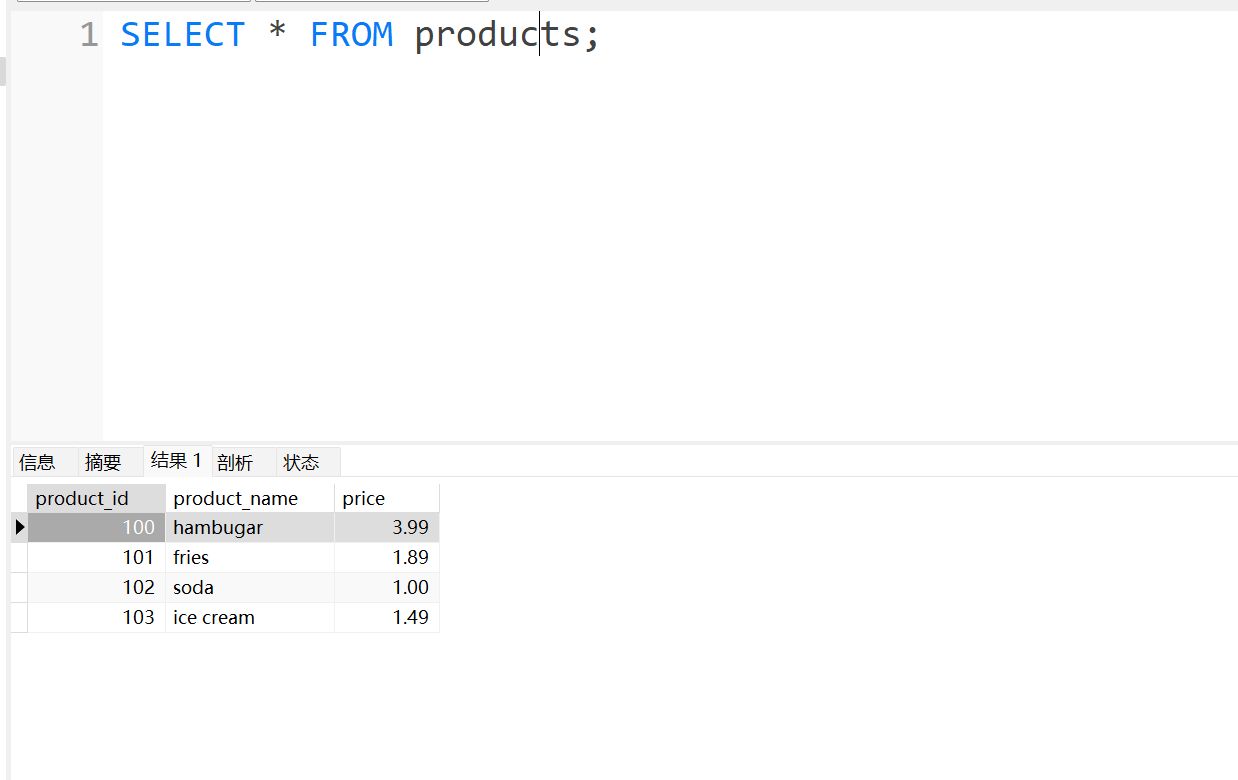
SELECT * FROM products;
接下来实战一下,可以看到 unique 有什么作用
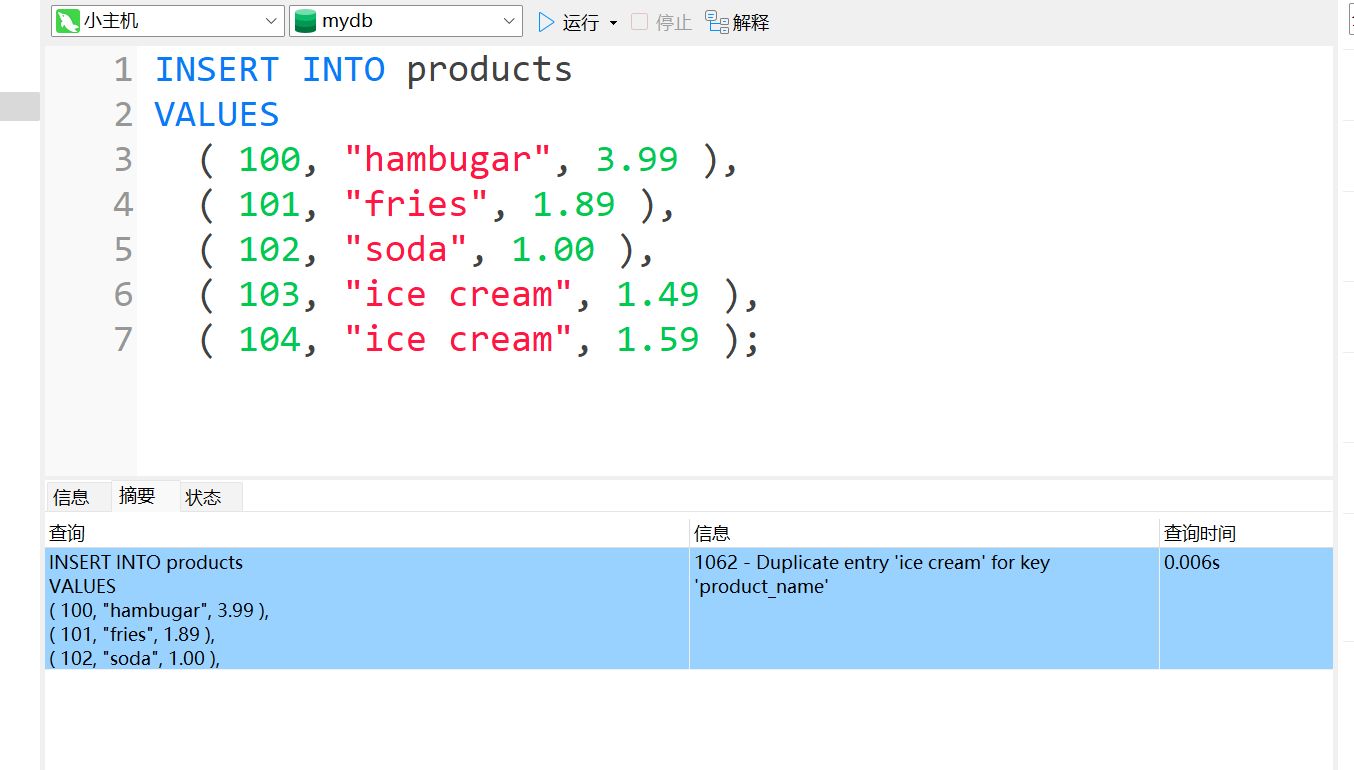
这样写就正常了
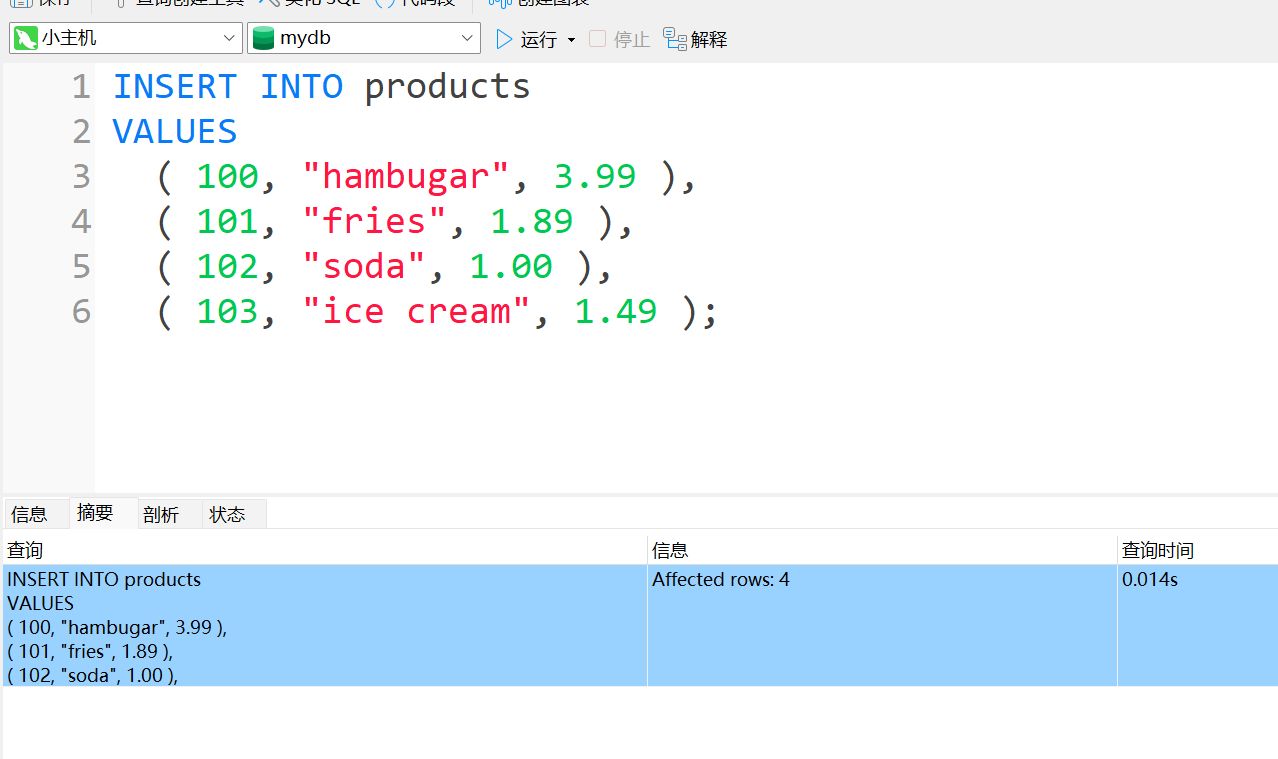
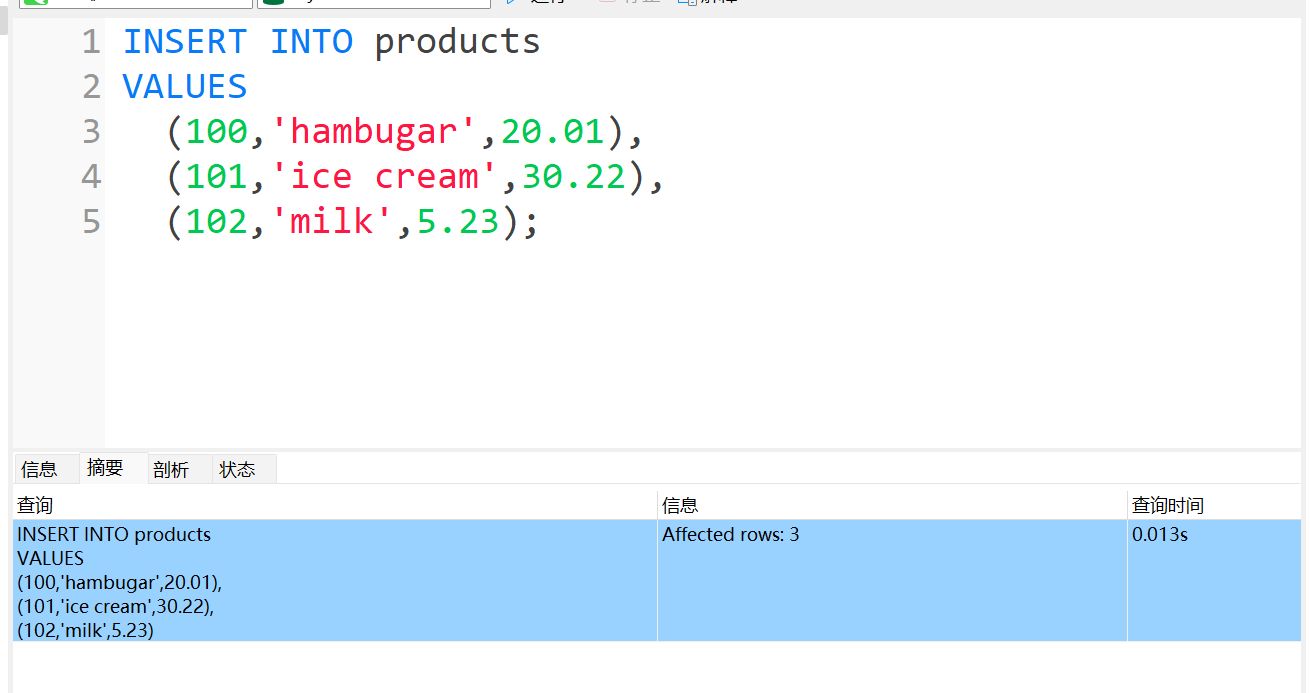
关于 NOT NULL#
NOT NULL 约束用于保证列的值不能为空(NULL)。它的语法格式为:
sql column_name datatype NOT NULL
CREATE TABLE products(
product_id INT,
product_name VARCHAR(25),
price DECIMAL(4,2) NOT NULL
);
CREATE TABLE products(
product_id INT,
product_name VARCHAR(25),
price DECIMAL(4,2)
);
ALTER TABLE products
MODIFY price DECIMAL(4,2) NOT NULL;
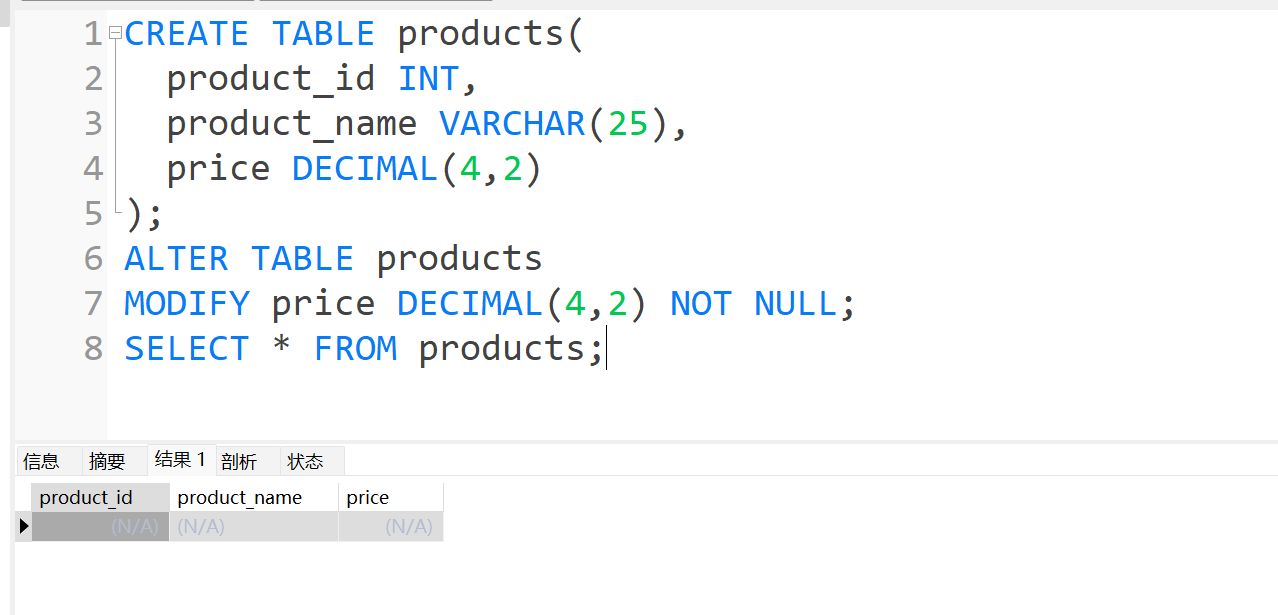
实战报错:
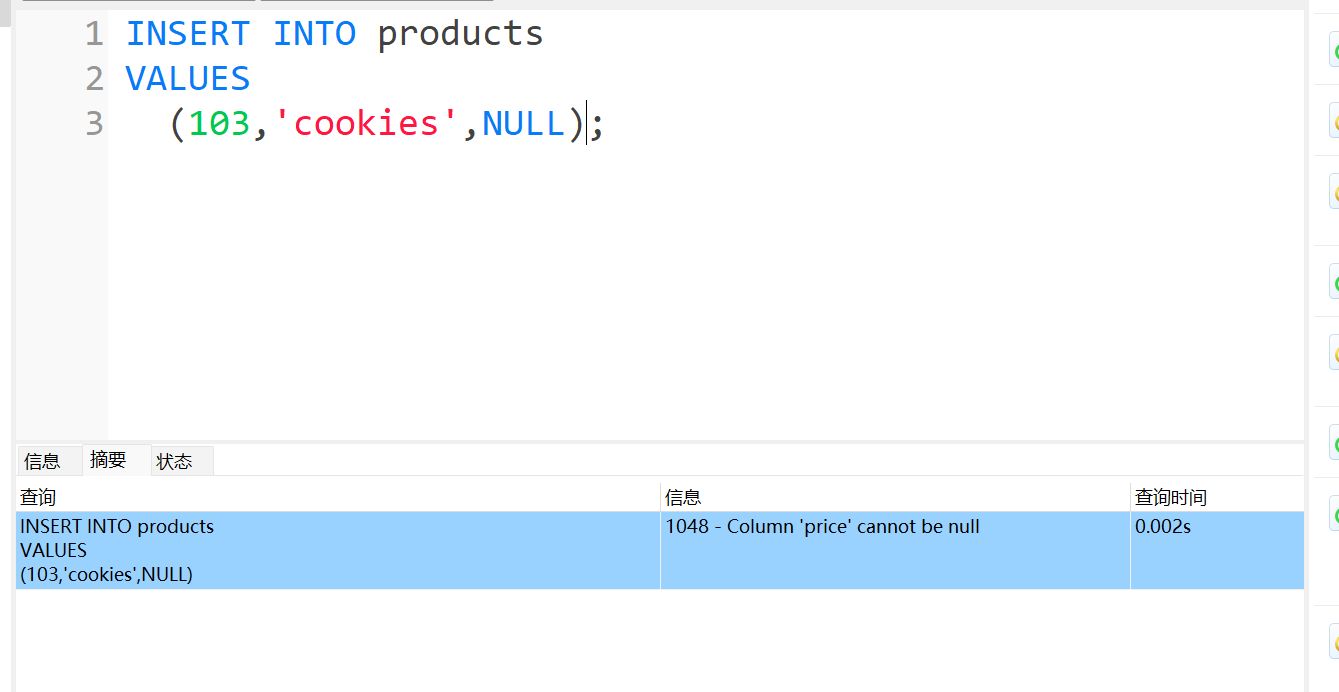
正确演示:
关于 CHECK#
CHECK 约束用于限制列中的值范围,保证数据的完整性。它的语法格式为:
column_name datatype CHECK (condition)condition 是要求列必须满足的条件,可以是比较运算符、BETWEEN、IN 运算符等。
创建
CREATE TABLE employees_test (
employee_id INT,
first_name VARCHAR(50),
last_name VARCHAR(50),
hourly_pay DECIMAL(5,2),
hire_date DATE,
CONSTRAINT chk_hourly_pay CHECK (hourly_pay >= 10.00)
);
追加
ALTER TABLE employees
ADD CONSTRAINT chk_hourly_pay CHECK(hourly_pay >= 10.00);
在 MySQL 中,CHECK 约束是被支持的,但是并不被实际执行。也就是说,虽然你在创建表时定义了 CHECK 约束,但是 MySQL 并不会在插入数据时执行该约束,也不会报错。所以,即使你插入了不符合 CHECK 约束的数据,MySQL 也不会报错,而是会继续插入该数据。
关于 DEFAULT#
在 SQL 中,DEFAULT 关键字用于为列定义默认值。当向表中插入新行时,如果未显式为某列指定值,则会使用默认值。默认值使我们无需每次插入新行时都指定每个列的值,有助于简化插入语句和提高效率。
CREATE TABLE products (
product_id INT,
product_name VARCHAR(50),
price DECIMAL(4,2) DEFAULT 0
);
如果表已经存在
ALTER TABLE products
ALTER price SET DEFAULT 0
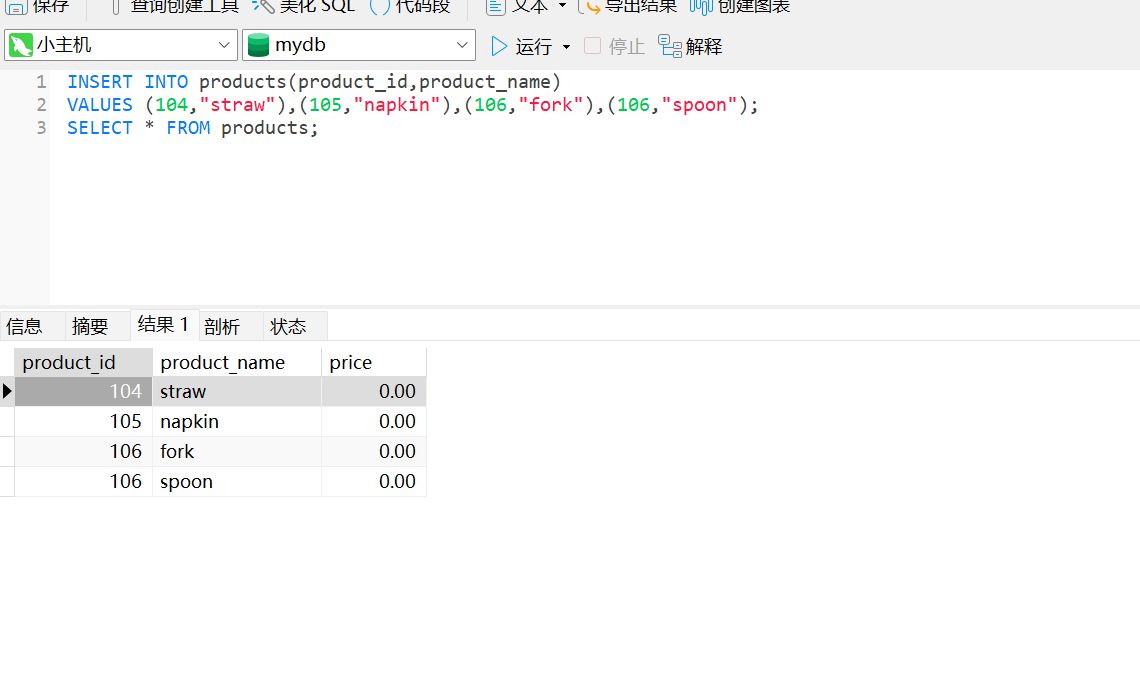
我们插入数据
INSERT INTO products(product_id,product_name)
VALUES (104,"straw"),(105,"napkin"),(106,"fork"),(106,"spoon");
SELECT * FROM products;
关于 PRIMARY KEY#
在 SQL 中,PRIMARY KEY(主键)是一种约束条件,用于标识表中的一列或多列,它们的值唯一标识每行数据。主键可以确保表中每行数据的唯一性,因此它通常被用作表中的索引。主键可以是一个或多个列,但通常都是使用单个列作为主键。
在创建表时,可以将主键定义为一个列或多个列的组合。主键可以通过以下两种方式定义:
- 在列定义时,使用 PRIMARY KEY 关键字将该列指定为主键。
- 在列定义后,使用 ALTER TABLE 命令将列指定为主键。
一个表只能有一个主键,主键的值不能为 NULL,因为主键用于标识每行数据,如果主键为空,那么就无法唯一标识每行数据。如果要在表中使用多个列作为主键,可以使用复合主键,这种情况下,每个列的值的组合必须唯一标识每行数据。
主键还可以用于定义外键,外键是一个表中的列,它引用另一个表中的主键列。外键用于确保表之间的数据一致性,它定义了两个表之间的关系,可以用于防止在一个表中插入无效的数据,以及在删除一个表中的数据时,自动删除相关的数据。
主键是唯一且不能为空的
主键是一种唯一且不能为空的标识符,可以用于唯一标识表中的每一行数据。就像人们的身份证号一样,每个人的身份证号都是唯一的,用于唯一标识一个人。同样地,每行数据的主键也必须是唯一的,以便可以唯一标识该行数据。主键可以由一个或多个列组成,但每个主键值的组合必须是唯一的。
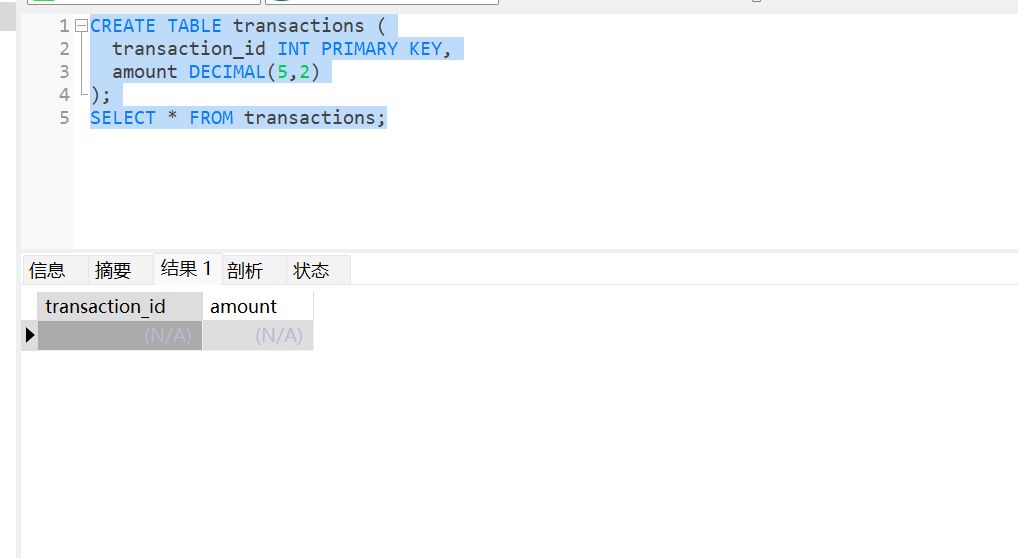
CREATE TABLE transactions (
transaction_id INT PRIMARY KEY,
amount DECIMAL(5,2)
);
SELECT * FROM transactions;
如果已经存在表,可以直接修改 id 为主键
ALTER TABLE transactions
ADD CONSTRAINT
PRIMARY KEY(transaction_id);
SELECT * FROM transactions;
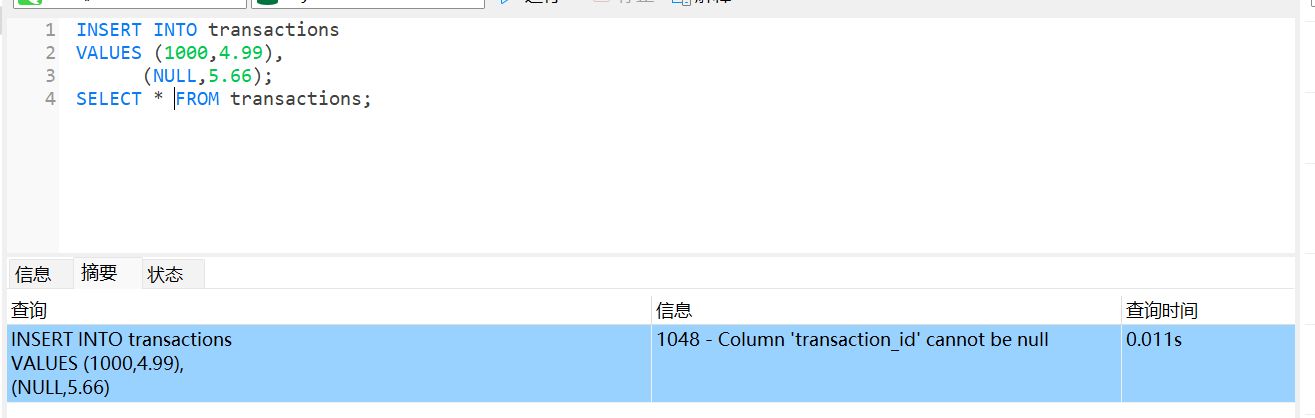
从上图我们可以知道,主键不能为 NULL
关于 AUTO_INCREAMENT#
在 MySQL 中,AUTO_INCREMENT 是一种列属性,它可以为表中的某一列指定一个自动增长的整数值,每次插入新记录时,该列的值都会自动递增。通常情况下,AUTO_INCREMENT 属性应该用于定义主键列,以确保每行数据都有唯一的标识符。
可以通过在表定义中使用 AUTO_INCREMENT 关键字来为表中的某个列指定自动增长属性,例如:
CREATE TABLE customers (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
email VARCHAR(50)
);
在上面的例子中,id 列被指定为主键,并使用 AUTO_INCREMENT 属性,因此每次插入新记录时,id 列的值都会自动递增。
CREATE TABLE transactions (
transaction_id INT PRIMARY KEY AUTO_INCREMENT,
amount DECIMAL(5,2)
);
SELECT * FROM transactions;
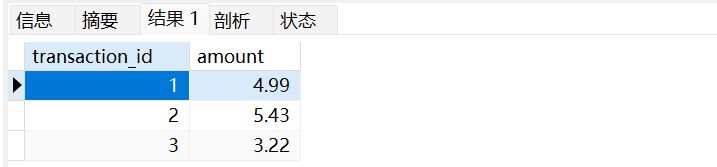
INSERT INTO transactions(amount)
VALUES (4.99),(5.43),(3.22);
SELECT * FROM transactions;
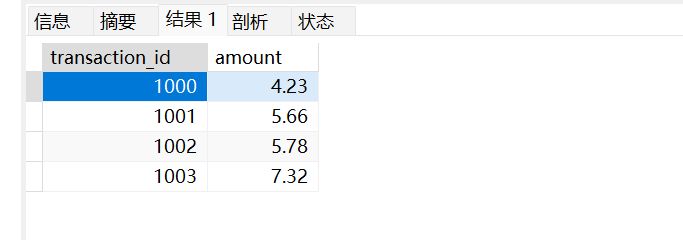
设置自增起始值
ALTER TABLE transactions
AUTO_INCREMENT = 1000;
INSERT INTO transactions(amount)
VALUES (4.23),(5.66),(5.78),(7.32);
SELECT * FROM transactions;
关于 FOREIGN KEY#
在 MySQL 中,FOREIGN KEY(外键)是一种约束条件,用于指定一个表的列与另一个表的列之间的关系。外键用于确保表之间的数据一致性,它定义了两个表之间的关系,可以用于防止在一个表中插入无效的数据,以及在删除一个表中的数据时,自动删除相关的数据。
外键通常用于建立表与表之间的关联关系,例如在关系型数据库中,可以使用外键将一张表中的列与另一张表中的主键列关联起来。在 MySQL 中,可以在创建表时使用 FOREIGN KEY 关键字来定义外键,例如:
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(id)
);
在上面的例子中,orders 表中的 customer_id 列被定义为一个外键,它引用了 customers 表中的 id 列。这意味着,orders 表中的每个 customer_id 值必须存在于 customers 表的 id 列中。如果尝试向 orders 表中插入一个 customer_id 值,而该值不存在于 customers 表中的 id 列中,则会引发一个错误。
案例:
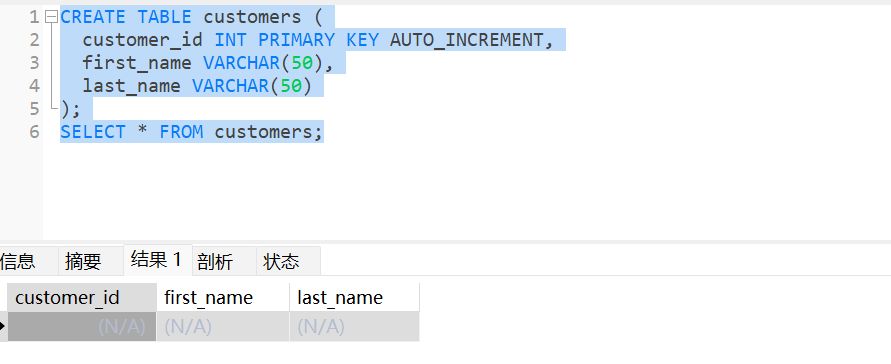
创建 customers 表
CREATE TABLE customers (
customer_id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50),
last_name VARCHAR(50)
);
SELECT * FROM customers;
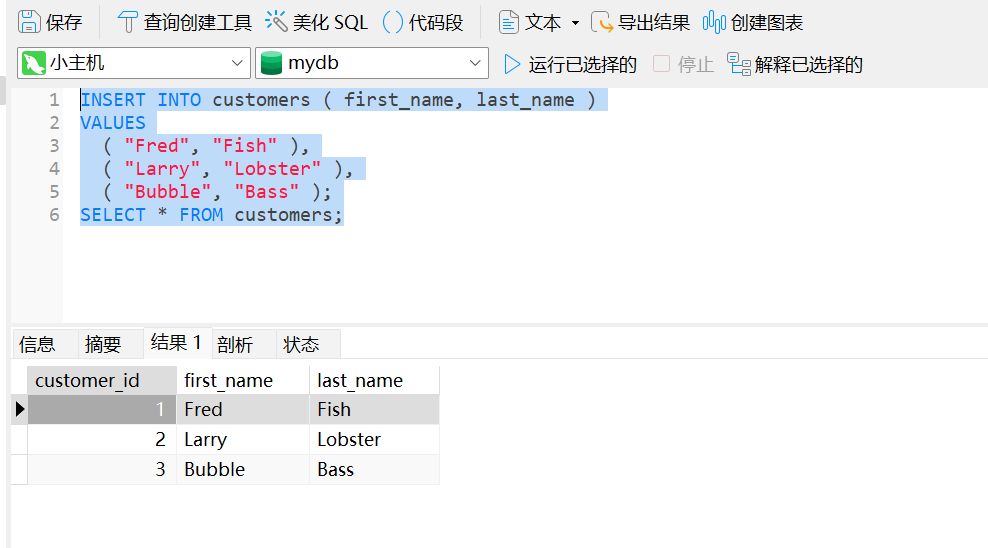
插入数据到 customers 表
INSERT INTO customers ( first_name, last_name )
VALUES
( "Fred", "Fish" ),
( "Larry", "Lobster" ),
( "Bubble", "Bass" );
SELECT * FROM customers;
创建 transaction 表
CREATE TABLE transactions (
transaction_id INT PRIMARY KEY AUTO_INCREMENT,
amount DECIMAL(5,2),
customer_id INT,
FOREIGN KEY(customer_id) REFERENCES customers(customer_id)
);
SELECT * FROM transactions;
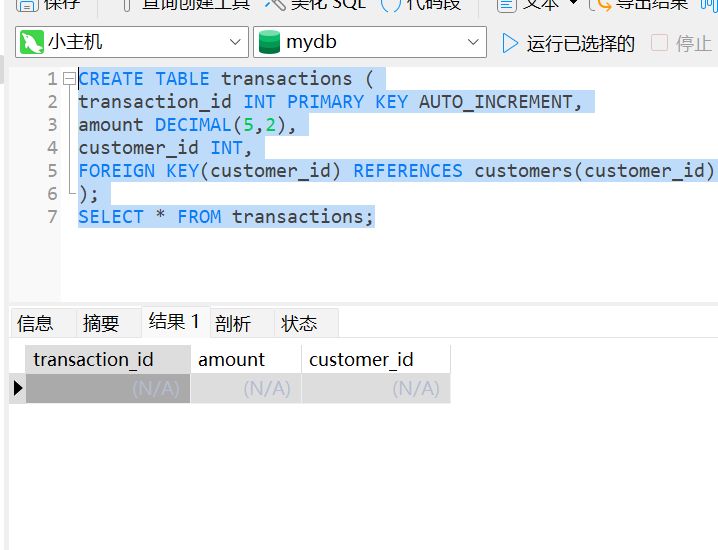
插入数据
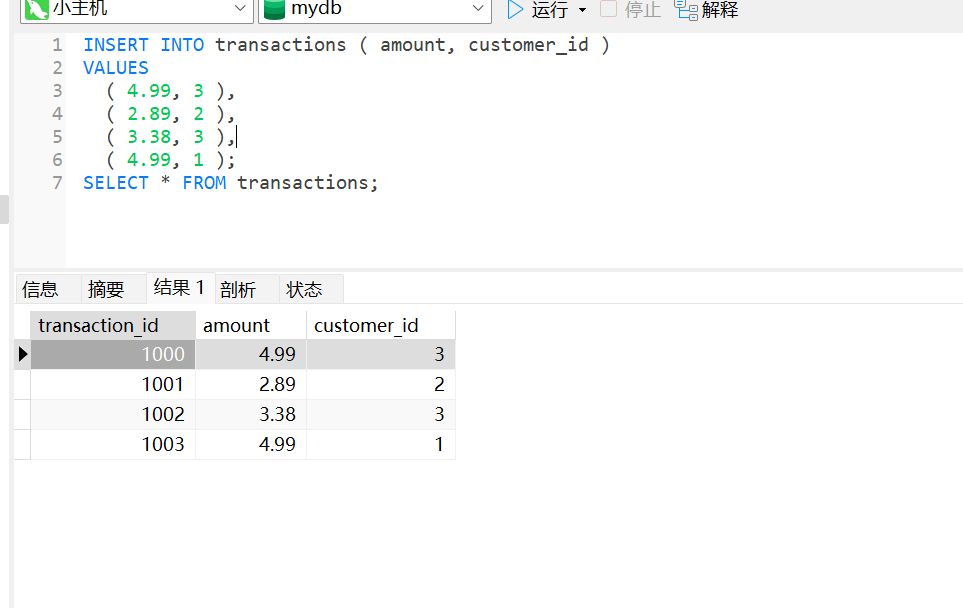
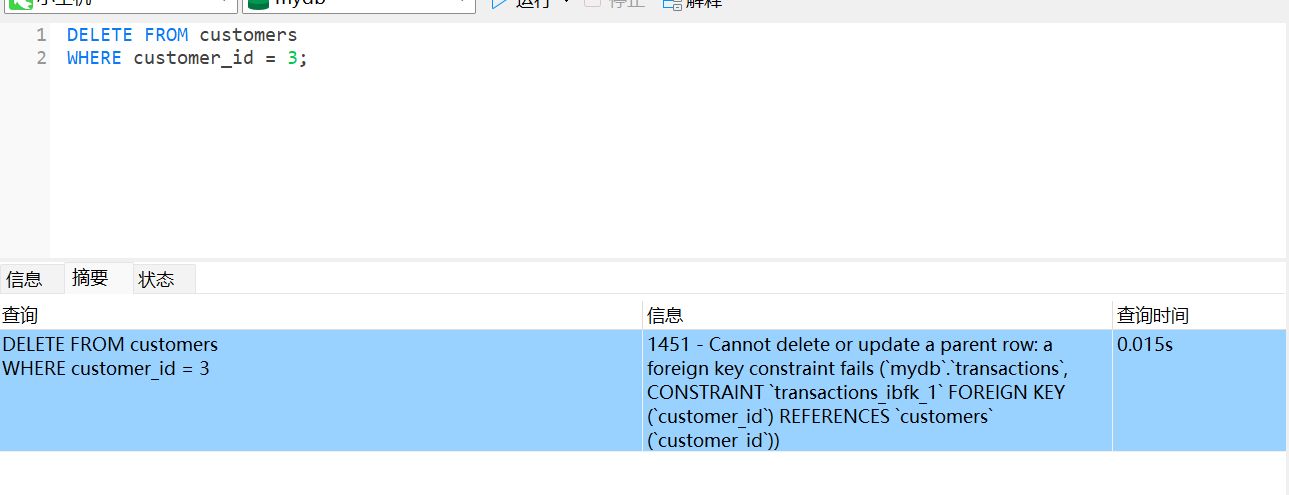
接下来我们尝试删除 customers 表中的一个人,但是这个人和 transactions 中的一个字段相关联
我们就会得到下面的报错
关于 JOINS#
在 MySQL 中,JOIN 是一种用于将两个或多个表中的数据组合在一起的操作。JOIN 操作基于两个或多个表之间的关系,它将一张表中的数据与另一张表中的数据进行匹配,以便从这些表中检索相关的数据。
MySQL 中有多种类型的 JOIN 操作,包括 INNER JOIN、LEFT JOIN、RIGHT JOIN 和 FULL OUTER JOIN。下面是各种 JOIN 操作的说明:
- INNER JOIN:返回两个表中匹配的行。它只返回两个表中都存在的行。
SELECT *
FROM table1
INNER JOIN table2
ON table1.column = table2.column;
- LEFT JOIN:返回左表中的所有行以及右表中匹配的行。如果右表中没有匹配的行,则返回 NULL 值。
SELECT *
FROM table1
LEFT JOIN table2
ON table1.column = table2.column;
- RIGHT JOIN:返回右表中的所有行以及左表中匹配的行。如果左表中没有匹配的行,则返回 NULL 值。
SELECT *
FROM table1
RIGHT JOIN table2
ON table1.column = table2.column;
- FULL OUTER JOIN:返回两个表中的所有行。如果某个表中没有匹配的行,则返回 NULL 值。
SELECT *
FROM table1
FULL OUTER JOIN table2
ON table1.column = table2.column;
在使用 JOIN 操作时,需要指定两个表之间的关系,这通常通过使用 ON 关键字来实现。ON 关键字用于指定两个表之间的关联条件,例如:
SELECT *
FROM orders
INNER JOIN customers
ON orders.customer_id = customers.id;
在上面的例子中,orders 表和 customers 表之间的关联条件是 orders.customer_id = customers.id。这意味着,只有 orders 表中的 customer_id 值与 customers 表中的 id 值匹配时,才会返回相关的行。
JOIN 操作也可以使用 WHERE 子句来指定关联条件,例如:
SELECT *
FROM orders, customers
WHERE orders.customer_id = customers.id;
在上面的例子中,orders 表和 customers 表之间的关联条件是 orders.customer_id = customers.id。这种写法与使用 INNER JOIN 操作是等价的。
INNER JOIN 实战#
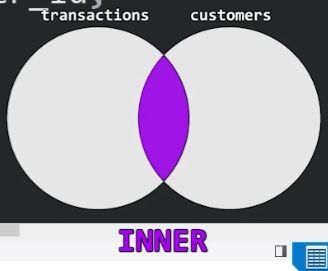
我们先来看一下 transactions 表和 customers 表中的内容
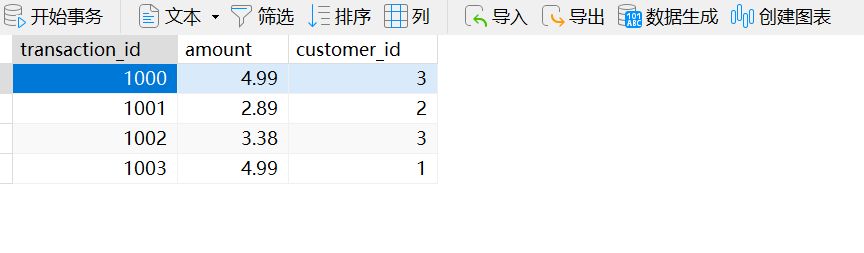
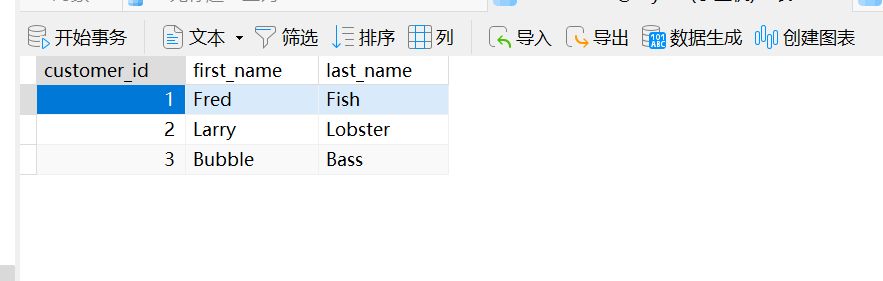
SELECT *
FROM transactions INNER JOIN customers
ON transactions.customer_id = customers.customer_id;
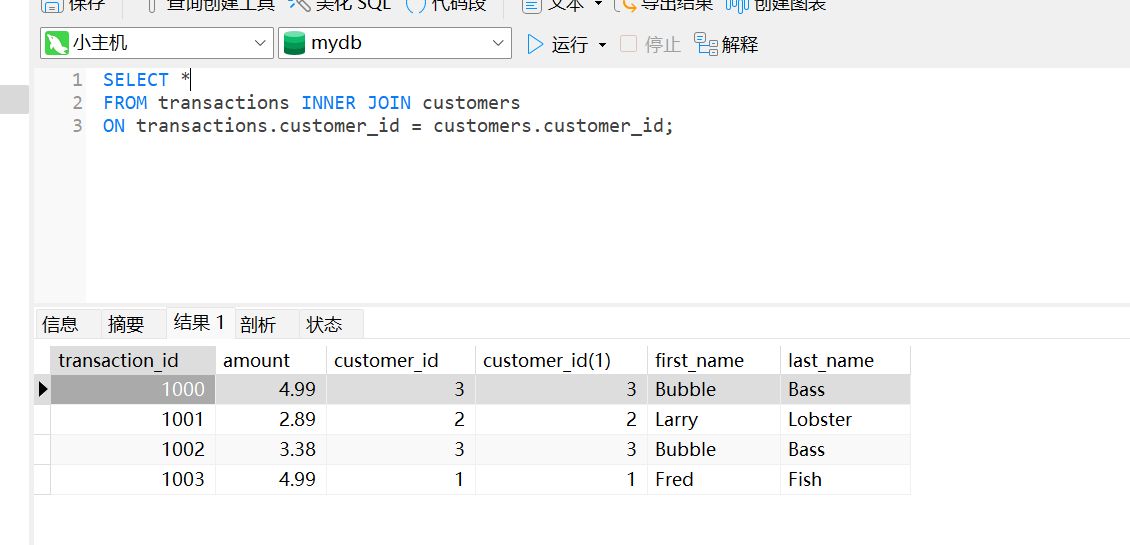
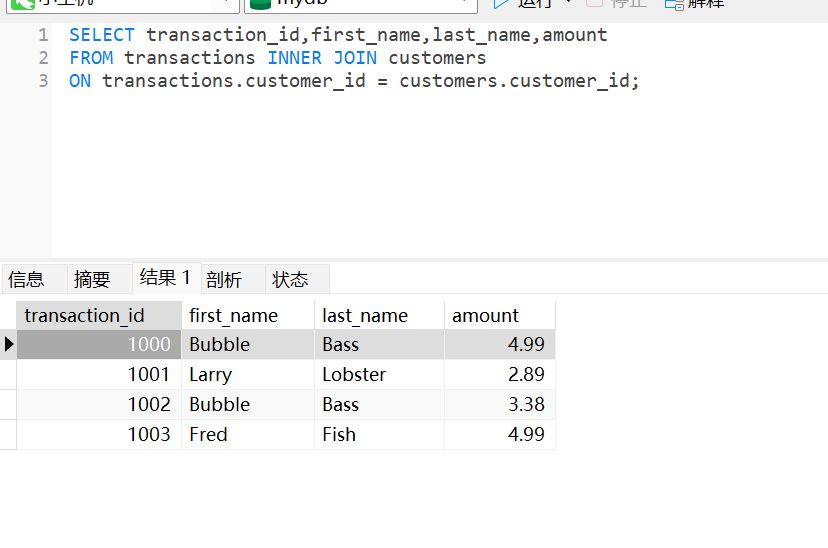
可以看到,我们这样拼起来,就能清晰的获得到用户的
transaction_id还有name,以及消费的amount上面的代码中,我们使用
customer_id这个属性把两个表连接起来
实战 LEFT JOIN,RIGHT JOIN#

现在我们往 transactions 表中插入一个没有 customer_id 属性的字段
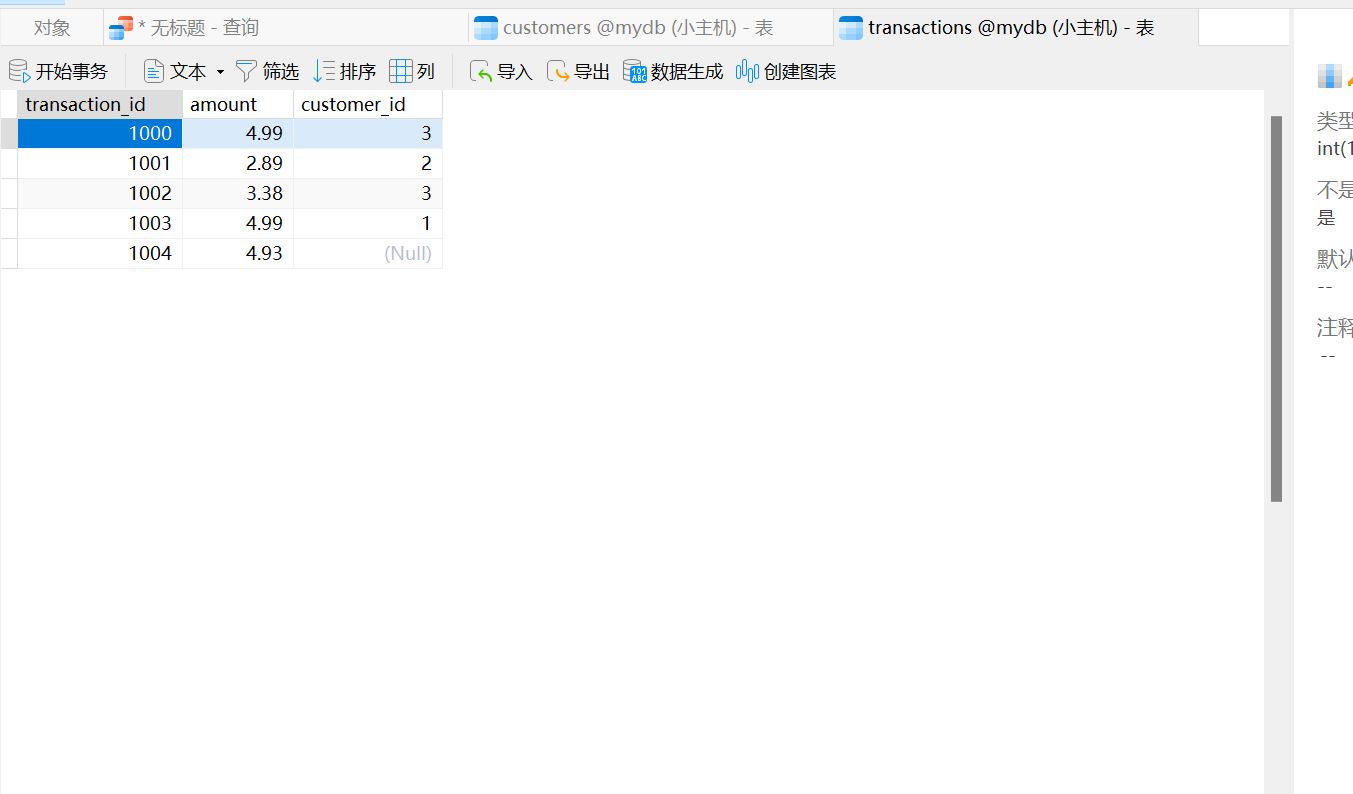
INNER JOIN 结果是这样的
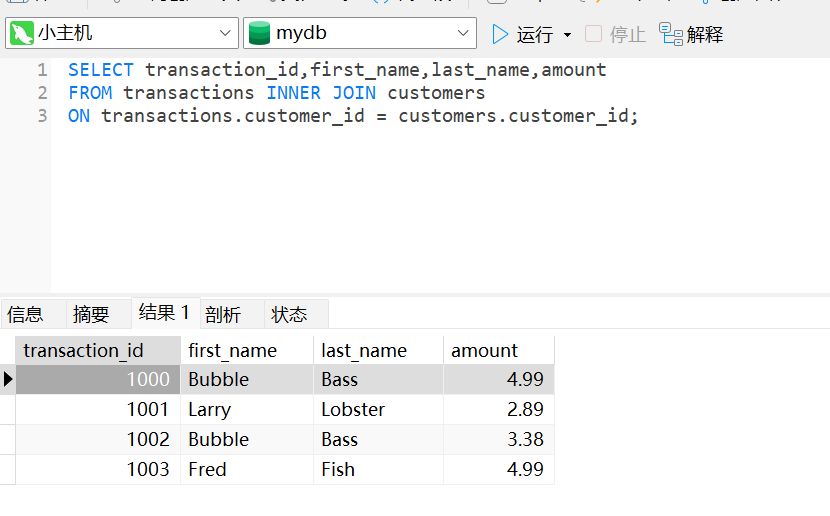
LEFT JOIN 是这样的
RIGHT JOIN 是这样的
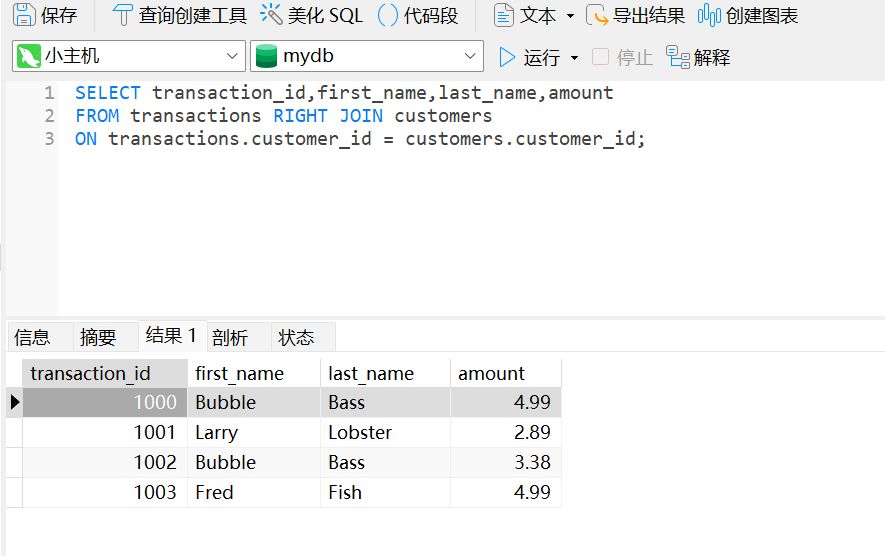
关于 ON#
在 MySQL 中,ON 关键字用于指定两个表之间的关联条件。在使用 JOIN 操作时,需要指定两个表之间的关系,这通常通过使用 ON 关键字来实现。
ON 关键字后面的条件指定了两个表之间的关联条件,它可以是一个简单的条件,也可以是一个复杂的条件。例如:
SELECT *
FROM orders
INNER JOIN customers
ON orders.customer_id = customers.id;
在上面的例子中,使用 INNER JOIN 操作将 orders 表和 customers 表连接起来,并指定了 orders.customer_id = customers.id 作为两个表之间的关联条件。这意味着,只有 orders 表中的 customer_id 值与 customers 表中的 id 值匹配时,才会返回相关的行。
ON 关键字后面的条件可以使用多个运算符和函数,例如:
- 等于运算符(=)
SELECT *
FROM orders
INNER JOIN customers
ON orders.customer_id = customers.id;
- 不等于运算符(<>)
SELECT *
FROM orders
INNER JOIN customers
ON orders.customer_id <> customers.id;
- 大于运算符(>)
SELECT *
FROM orders
INNER JOIN customers
ON orders.order_date > customers.join_date;
- 小于运算符(<)
SELECT *
FROM orders
INNER JOIN customers
ON orders.order_date < customers.join_date;
- IN 运算符
SELECT *
FROM orders
INNER JOIN customers
ON orders.customer_id IN (1, 2, 3);
- LIKE 运算符
SELECT *
FROM orders
INNER JOIN customers
ON customers.name LIKE 'J%';
- 函数
SELECT *
FROM orders
INNER JOIN customers
ON YEAR(orders.order_date) = YEAR(customers.join_date);
在使用 ON 关键字时,需要确保关联条件是正确的,并且可以确保正确地关联两个表。如果关联条件不正确,则可能会导致错误的查询结果。
关于 AND,OR,NOT#
在 MySQL 中,AND、OR 和 NOT 是逻辑运算符,用于组合和操作多个条件。下面是一些使用 AND、OR 和 NOT 运算符的示例:
- AND 运算符
AND 运算符用于组合多个条件,并返回同时满足这些条件的行。例如:
SELECT *
FROM customers
WHERE age > 18 AND gender = 'F';
上面的查询将返回所有年龄大于 18 岁且性别为女性的客户。
- OR 运算符
OR 运算符用于组合多个条件,并返回满足任意一个条件的行。例如:
SELECT *
FROM customers
WHERE age > 18 OR gender = 'F';
上面的查询将返回所有年龄大于 18 岁或性别为女性的客户。
- NOT 运算符
NOT 运算符用于否定一个条件,返回不满足该条件的行。例如:
SELECT *
FROM customers
WHERE NOT age > 18;
上面的查询将返回所有年龄小于或等于 18 岁的客户。
- 组合使用 AND、OR 和 NOT 运算符
AND、OR 和 NOT 运算符可以组合使用,以便更复杂的条件筛选。例如:
SELECT *
FROM customers
WHERE age > 18 AND (gender = 'F' OR city = 'New York') AND NOT status = 'inactive';
上面的查询将返回所有年龄大于 18 岁、性别为女性或住在纽约市、且状态不为“inactive”的客户。
需要注意的是,在使用 AND、OR 和 NOT 运算符时,需要使用括号来明确条件的优先级,以便确保条件组合的正确性。
关于 LIKE#
在 MySQL 中,LIKE 是一种模式匹配运算符,用于在字符串中查找指定的模式或子字符串。LIKE 运算符通常与通配符一起使用,以便更灵活地匹配字符串。
LIKE 运算符的语法如下:
SELECT column_name(s)
FROM table_name
WHERE column_name LIKE pattern;
其中,column_name 是要匹配的列名,table_name 是要查询的表名,pattern 是要匹配的模式或子字符串。pattern 可以包含通配符,以便更灵活地匹配字符串。
在 MySQL 中,LIKE 运算符支持两种通配符:
- 百分号(%):表示零个或多个字符。例如,'a%' 匹配以字母 a 开头的任何字符串,'%a' 匹配以字母 a 结尾的任何字符串,'%a%' 匹配包含字母 a 的任何字符串。
- 下划线():表示一个字符。例如,'a' 匹配以字母 a 开头且长度为两个字符的任何字符串,'_a' 匹配以字母 a 结尾且长度为两个字符的任何字符串。
下面是一些使用 LIKE 运算符的示例:
- 查找以 'J' 开头的所有客户名:
SELECT *
FROM customers
WHERE name LIKE 'J%';
- 查找包含 'doe' 子字符串的所有客户名:
SELECT *
FROM customers
WHERE name LIKE '%doe%';
- 查找以 'j' 开头且长度为 4 个字符的所有客户名:
SELECT *
FROM customers
WHERE name LIKE 'j___';
- 查找以 'j' 开头或以 's' 结尾的所有客户名:
SELECT *
FROM customers
WHERE name LIKE 'j%' OR name LIKE '%s';
需要注意的是,LIKE 运算符对于大型数据集可能会导致性能问题,因为它需要对每个字符串执行模式匹配。如果要进行高效的字符串匹配,可以考虑使用全文本搜索引擎,如 MySQL 提供的全文本搜索引擎 MyISAM 或 InnoDB 引擎中的全文本搜索插件。
MYSQL Function#
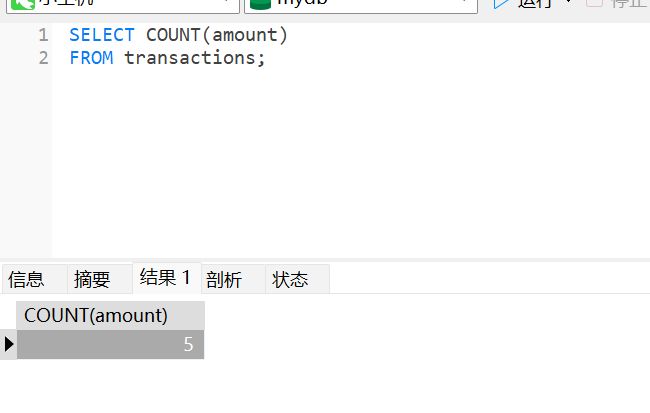
比如,我现在有个需求,计算上面消费次数
SELECT COUNT(amount)
FROM transactions;
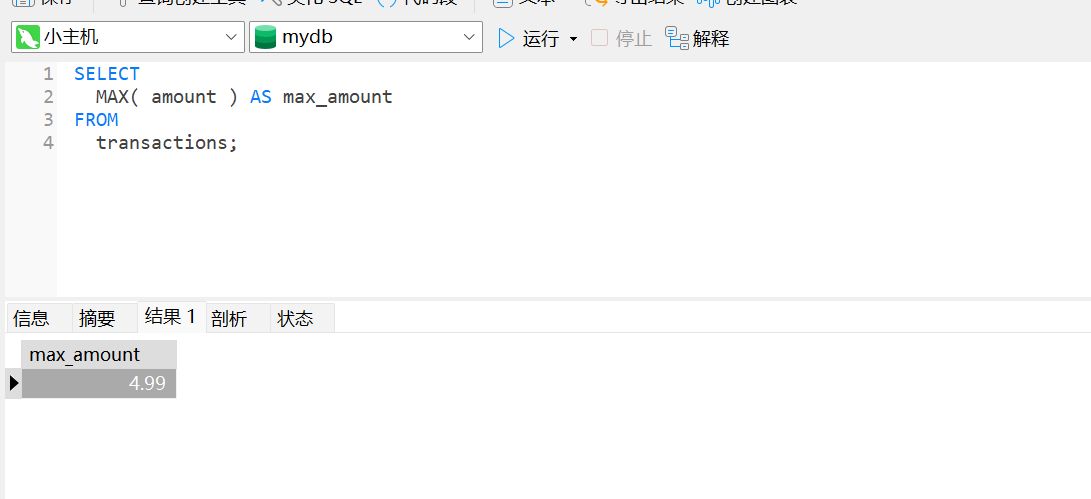
SELECT
MAX( amount ) AS max_amount
FROM
transactions;
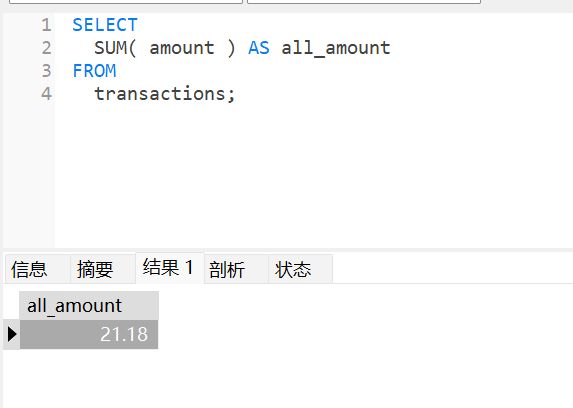
SELECT
SUM( amount ) AS all_amount
FROM
transactions;
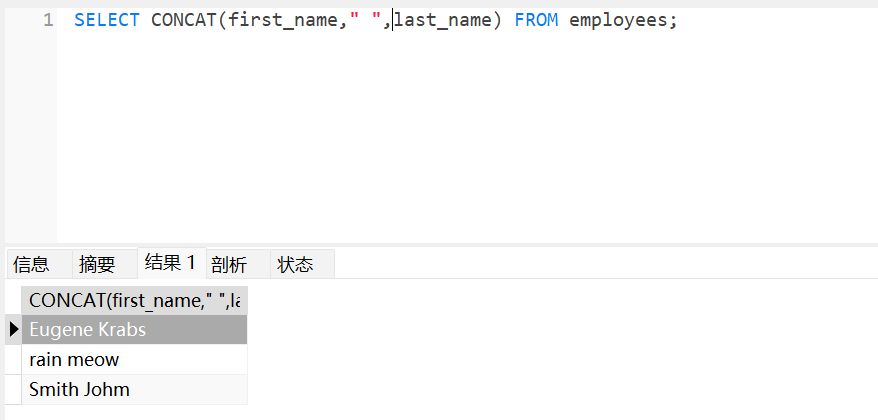
链接字符串
employee 表内容
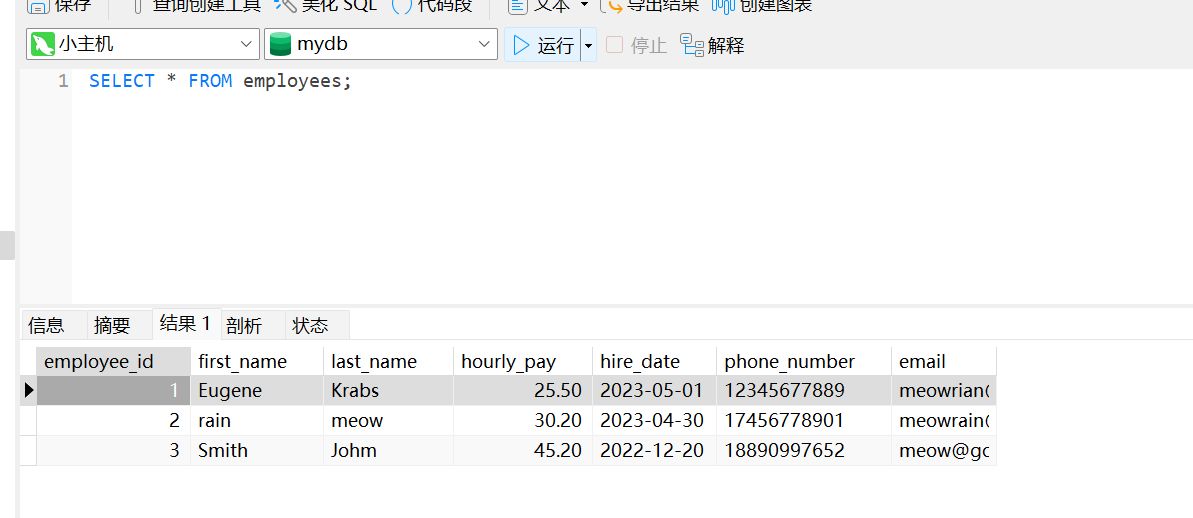
接下来我们尝试把名字连起来
SELECT CONCAT(first_name," ",last_name) FROM employees;